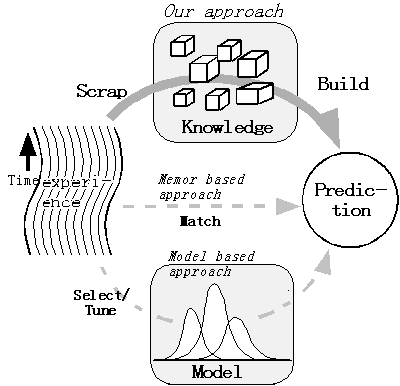
Figure 1. Approaches for prediction
ü@
ü@
To improve the prediction ability of an intelligent system, information should be decomposed into reusable parts, each of which contains a rule. We firstly propose a new criterion called Matchability suitable for the decomposition of real world information, and then propose a decomposition method. We developed a search algorithm for decomposition. Simulation demonstrates that the algorithm can decompose mixed situations. This technology is effective for pre-processing of data analysis and pattern recognition.
ü@
Keywords: Self-organization, Data analyses
We propose information segmentation technology for advanced prediction and criterion for this purpose.
Memory based reasoning (MeBR) is shown by a broken line of the center of Fig. 1. MeBR, which directly uses empirical data, can only use neighboring events for prediction. The prediction power is low in that MeBR cannot predict if any neighboring events are non-existing. To carry out prediction from a small empirical data, the utilization of a distant event becomes a key technology.
The lower broken line in Fig. 1 shows the prediction by typical model based reasoning (MoBR). All events are utilized indirectly, because prediction is executed through a model that accumulates the influence of all events.
The upper side of Fig. 1 shows our prediction approach. The border-less empirical data is scraped into highly reusable small parts. A system makes a prediction by building up these parts. The prediction system can handle unknown input by combining partial empirical data, and thus has generalization capability. The proposed situation decomposition method that decomposes empirical data is an element technology for a scrap and build prediction approach. Our approach is more modest than MoBR, because far events exert influence on the prediction value in MoBR but only provide a decomposition cue in our approach.
ü@
Figure 1. Approaches for prediction
From the viewpoint of learning, reinforcement learning is not fit for situation decomposition, because the credit assignment problem becomes prominent; we therefore adopt a self-organization method. Thereupon, matchability criterion as a general inside evaluation standard for the self-organization method is proposed.
We call the technology that decomposes the data situation decomposition. Information that an intelligent system takes in from the real world is events (feature vectors) which lined up toward time and each element of an event is pattern information without the semantics. We call an event set that a system handles a whole situation.
There are many (1) feature selecting technologies and (2) event selecting technologies in the field of pattern recognition. However, the situation decomposition proposed in this manuscript differs from many technologies in the point that (3) both event and feature are selected simultaneously. Situation decomposition method extracts matchable situations as shown in Fig. 2. The matchable situations correspond to local maximums of matchability criterion that are mentioned later.
ü@
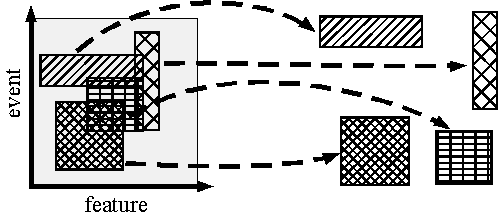
Fig.2 Situation decomposition extracts some matchable situations.
The proposed situation decomposition method extracts rule-containing partial situations. On the other hand, there are many technologies that extract a rule itself. The BACON algorithm [1] is the pioneer work of discovering rules between features. Recently, research has been advancing on extracting rules from large-scale databases through data mining [2]. Approximate functional dependency technique is similar in the point of simultaneously selecting features and events [3].
There are three dominant purposes of acquiring the inside structure automatically from sample data. They are "prediction improvement", "data compression", and "visualization". The proposed matchability criterion is one kind of the information criteria that aims at "prediction improvement". Information criteria are often used for model selection technology and data compression. First of all a general view of these is given.
MoBR chooses a unique model instance that explains sample data well out of a model class that reflects the a priori knowledge in the problem field. On the designed model class, each model instance is evaluated by using a knowledge-reflecting factor that shows the degree of influence exerted by a priori knowledge. The fundamental composition that appears to a model selection criterion is a trade off between a data-explaining factor and a knowledge-reflecting factor. When there are not any priori knowledge, a knowledge-reflecting factor is replaced to unstructured factor. A method that adopts entropy maximization as an unstructured factor is often used.
There is the problem that the selected instance is dependent on the value of an arbitrary constant that adjusts the balance of a data-explaining factor and knowledge-reflecting factor in the entropy maximization method. To avoid arbitrariness, there is Akaike's Information-theoretic Criterion (AIC) that leads trade off uniformly from an expected average logarithm likelihood [4]. AIC is defined as the number of free parameters minus the maximum logarithm likelihood. The unique model instance that minimizes the criterion is chosen. Maximum logarithm likelihood represents a data-explaining factor and the minimization of the number of free parameters represents a knowledge-reflecting factor.
In information theory, data compression technology is a practical problem. Therefore, information content is used as the evaluation standard. A feature selector based on data compression technology selects a mutually independent feature.
The Minimum Description Length (MDL) principle was developed at the meeting point of model selection and data compression technology [5,6]. MDL states that the "best model minimizes the number of bits necessary to code data including model" and does not contain arbitrary constants like AIC. The shortness of a description length of data represents a data-explaining factor, because the shorter the coded data length the more precisely the model reflects the data distribution. The minimization of the description length of a model represents a knowledge-reflecting factor.
We propose matchability criterion to evaluate the reusability of the partial situations extracted by the situation decomposition method. The chance of a matching opportunity is used to estimate reusability, because an empirical data is always utilized through matching. Matchability criteria include the following 3 factors. [Event-increasing factor] Reliability increases as the number of events that do matching increases. [Feature-increasing factor] A partial situation that includes many features is better in that mutual predictability between features is improved. [Structured factor] A partial situation that has low entropy and many events in a small region is better. Here feature-increasing factors and event-increasing factors are a data-explaining factor. A fundamental tradeoff exists between a structured factor and a data-explaining factor. This tradeoff originates from the general tendency that "structure is being lost as the number of features and events increases, because all features and an event do not have a strong mutual relations". And there is a tradeoff between feature-increasing factors and event-increasing factors. Matchability criterion stands on the principle that "a particular causality in the real world reflects the relation between particular features"
Matchability criterion is differ from many other criteria in the point that it evaluates partial situations without considering the whole problem space, although it is a criterion to estimate the inside structure of an information source. In terms of the following points, our criterion differs from model selection criteria such as AIC and MDL in selecting a unique model instance. Firstly matchability criterion does not produce only a unique solution but rather many local solutions. Secondly, matchability criterion contains structured factors in contrast with unstructured factors that are one kind of a knowledge-reflecting factor. Furthermore matchability criterion selects strongly related features, unlike feature selection technology based on data compression.
The whole situation holds D events, each of which contains N elements. The vectors d, n indicate the selected features and events from the whole situation.
d = (déP, déQ,üc,dD): Feature selection vectorn = (n1, n2,üc,nN): Event selection vector
Vector elements di,ni are binary indicators of selection/unselection. The number of selected features is n. The number of selected events is d. The feature selection vector that selects all features is D. The event selection vector that selects all events is N. The situation decomposition method selects the some of partial situation J=(d, n) from 2D+N combination of all partial situations.
In the formalization in this paper, each feature is divided into si segments, and let the vector of the segment numbers be s= (séP, séQ,üc,sD).
The partial feature space is indicated by the feature selection
vector d. This space contains ![]() segments
(the product of the segment number that is selected.)
segments
(the product of the segment number that is selected.)
The vector rd indicates the selected segments in this partial feature space.
rd=(rdéP,rdéQ,üc,rdSd): Segment selection vector
Vector elements rdi are binary indicators of selection/unselection. The number of the segments selected is rd (0<rdüģSd). The events that are included in the selected segment are all selected. The partial situation that is indicated by a segment is J=(d, rd).
We take three factors (explained in Chapter 3) in account. The feature-increasing factor increases the number of all segments in partial feature space Sd. The event-increasing factor increases the number of selected events n. The structuring factor decreases the number of selected segments rd. The matchability criterion is defined as follows by combining these 3 variables.
Searching matchable situations J=(d, n) is searching local maximums of matchability criterion from the whole situation J=(D, N). It is basically carried out in the feature and event selection space. However, matchable situations J=(d, rd) are extracted by utilizing a segment, to speed up a search.
Below the procedure of a search is explained.
2) Search for a segment selection vector rd, which is a local maximum for the segment selection direction in the partial feature space indicated by d.
3) If the segment selection vector rd, that was chosen in process 2) is the local maximum with respect to the change of a feature selection, it is a matchable situation.
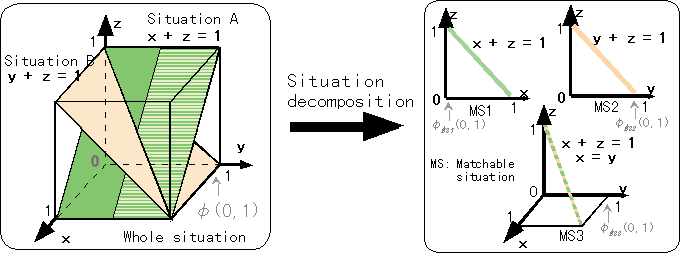
The simulation demonstrates the effect of situation decomposition. The whole situation is a combination of two partial situations in 3 dimensional feature space shown in Fig. 3. 11ü~11 events are arranged to notches at a regular interval of 0.1 on a plane in each partial situation. Situation A is the plane x+z=1 and situation B is the plane y+z=1. For situation decomposition, each feature in the range [-0.05, 1.05] is divided into 11 segments of 0.1 width. C1 = 1.0, C2 = 0.3, C3= 0.7 are used as the constants of the matchability criterion.
The result of situation decomposition is shown in the right half of Fig. 2 and Table 1. Matchable situations 1 and 2 correspond to each input situation A and B. However, matchable situation 3 is the new one that was made with a combination of two partial input situations and distributed on the straight line (x=y, x+z=1).
 ü@
ü@
Figure 3. Events on two plains in the cube decomposed to three matchable situations
We use the multi-valued function āė: (x, y)ü©z to explain the prediction improvement by the situation decomposition method. The MeBR that is applied to each matchable situation can output āėMS1(0,1)=1.0, āėMS2(0,1)=0.0, but simple MeBR outputs in the worst case only āė(0,1)=0.5, the mean value of the two situations. Even if the input situation A (x+z=1) lacks half of its parts, such that no data exists in the range y>0.5, our method extracts a matchable situation similar to MS1, according to an addition experiment. In this case, our method outputs āėMS1(0,1)=1.0, which is impossible by simple MeBR. Our method is useful in the situation separation and the generalization capability in this way.
We proposed a method that extracts matchable situations each of which contains a rule from the whole situation that is the collection of an event (feature vector) by using a new evaluation criterion called matchability. Matchable situations help prediction by generalization. Therefore, it may be used as the pre-processing in fields such as a data analysis, pattern recognition, reasoning, and an action decision.
ü@
We should refine the matchability criterion, because the present criterion contains arbitrary constants. To carry out advanced prediction, the mechanism that combines the decomposed empirical data is necessary. These kinds of technology are being developed briskly in the artificial intelligence field. We are also developing pattern based distributed intelligence architecture for this purpose [7]. Hereafter we try to approach real world intelligence from technology that is based on scrap and build of information.