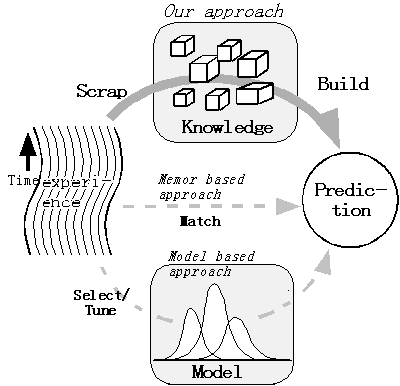
Fig.1 Approaches fo prediction
Email: yamakawa@flab.fujitsu.co.jp
Real World Computing Partnership
9-3, Nakase 1-Chome, Mihama-ku, Chiba City, Chiba 261-8588, Japan
知的システムの予測能力向上のためには、情報を再利用しやすい規則性の高い部分情報に分解する必要がある。本稿では実世界情報の分解に適したMatchabilityという新しい評価基準と分解手法を提案する。分解のための探索アルゴリズム開発し、これを計算機上に実装し、シミュレーションによりデータが分解される事を示した。この技術はデータ解析やパターン認識の前処理としての有効性が期待される。また状況毎の関連の強いデータを自己組織的に抽出する事ができる。Keywords: Matchability, Self-organization,
本稿では高度な予測能力の実現に必要な情報のセグメンテーション技術とそのための評価基準の提案を行う。
Fig.1の中央の破線で示すように、直接的に経験を用い予測を行うMemory based reasoning (MeBR)では距離が近いイベントのみを用いる。このために距離が近いイベントが存在しない場合に無力である点で予測能力が低い。少ない経験から予測を行うには距離が遠いイベントの活用が鍵となる。
典型的なModel based reasoning(MoBR)による予測をFig.1の下の破線で示す。まず全てのイベントの影響をモデルに蓄積し、モデルを通して予測を行うので、間接的に全てのイベントを利用できる。
我々が予測能力を向上させるためのアプローチをFig.1の上側の矢印で示す。まず予めセグメンテーションされていない経験を再利用性の高い小さな部品に分解し、次にその部品を再構成して予測を行う。こうすると未知の入力に対して過去の部分的な経験を組合わせによる予測を行うことで汎化能力が得られる。本稿ではその要素技術となる経験を分解するための状況分解技術を提案する。MoBRでは遠方のイベントの影響が値にまで影響を及ぼすのに比べて、我々のアプローチは控えめで、遠方のイベントは経験を分解するための手掛かりとして利用される。
Fig.1 Approaches fo prediction
学習の視点から見れば、強化学習を利用して状況を分解する方法も考えられるが、この目的ではCredit assignment問題が顕著となるので自己組織的な学習を用いる。そこで、自己組織化に用いる一般的な内部評価基準としてMatchability基準を提案する。
提案する経験を分解する技術を状況分解と呼ぶ事にする。実世界において知的システムが外界から取り込む情報は、時間方向に並んだイベント(特徴量ベクトル)であり、イベントの各要素は意味のラベル付がされていないパターン情報である。ここで、システムが有限時間内に取り扱うイベント集合を全体状況とする。
全体状況を分解する方法として(1)イベントを選択する技術や(2)特徴量を選択する技術がパターン認識の分野において数多く見られる。しかし本稿で提案する状況分解は、(3)イベントと特徴量の両方を同時に選択する点で多くの技術と異なる。状況分解ではFig.2に示すように与えられた全体状況から、後述するMatchability基準が極大値となる複数の規則性の高いMatchable状況を抽出する。
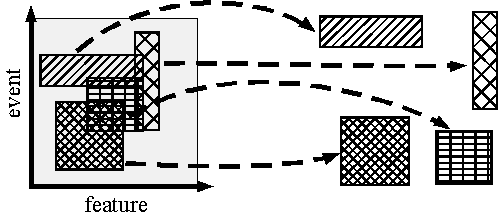
Fig.2 Situation decomposition extracts some matchable situations.
提案する状況分解は規則性の高い部分状況を抽出する。一方、規則そのものを抽出する技術は多数存在する。先駆的には特徴量間の関係を導くBACONアルゴリズム[1]が有名である。近年はデータマイニング分野で大量データから規則を抽出する研究が盛んである[2]。特に高須らによる近似的関数従属性の抽出では特徴量とイベントを同時に選択する点で関連が深い[3]。
標本データから自動的に内部構造を推定する主な目的には予測性の向上、データ圧縮、視覚化の3つがある。提案するMatchability基準は予測性の向上を目指す情報量規準の一種である。しばしば情報量規準が用いられるのはモデル選択技術とデータ圧縮技術であるので、まずこれらについて概観する。
MoBRでは対象領域における先験的知識を反映するモデルクラスの中から標本データを尤もよく説明するユニークなモデルインスタンスが選ばれる。設計されるモデルクラス内の各インスタンスには先験的知識の反映の程度を示す知識反映因子による評価が与えられる。モデル選択基準に現われる基本的構図は、データ説明因子と知識反映因子のトレードオフである。また対象領域の先見知識を利用できない場合には、知識反映因子は無構造化因子に置換えられる。無構造化因子にエントロピーに最大化を採用する方法は良く用いられる。
最大エントロピー法などでは、データ説明因子と知識反映因子のバランスを調整する任意定数の値に依存して選択されるインスタンスが変化する問題がある。恣意性を除いた基準として期待平均対数尤度から統一的にトレードオフを導く Akaike's Information-theoretic Criterion (AIC) [4]がある。AICは自由パラメタ数からモデルの最大対数尤度を引いた基準量を小さくするモデルを選ぶ。最大対数尤度がデータ説明因子を示し、自由パラメータ数の最小化が知識反映因子に相当する。
一方、情報理論においてデータ圧縮技術は現実的な課題であり、利用される評価基準は情報量である。データ圧縮に基づく特徴量選択をでは相互に独立な特徴量が選択される。
データ圧縮技術にモデル選択の思想が結びつくことでMinimum Description Length (MDL) [5,6]原理が導かれた。MDLは「与えられたデータを、モデル自身の記述も含めて最も短く符号化できるような確率モデルが最良のモデルである」と主張する基準で、AICと同様に任意定数を含まない。符号化されたデータの記述長が小さいことは、モデルがデータの分布を正確に反映したことを示すので、データの記述長の短さがデータ説明因子となる。また、モデルの記述長の最小化が知識反映因子を表わす。
状況分解で取り出す部分状況の再利用性を評価するための、Matchability基準を提案する。経験は常にマッチングを通して利用されるので、マッチング機会の多さを利用して再利用性を見積もる。Matchability基準は以下の3つの因子を含む。[イベント数増加因子]マッチングするイベントの数が多いほど信頼性が高い。[特徴量数増加因子]特徴量間の相互予測性を高めるために、多くの特徴量を含んでいる部分状況が良い。[構造化因子]多くのイベントが局在するエントロピーが小さい部分状況が良い。ここでは特徴量数増加因子とイベント数増加因子がデータ説明因子である。基本的なトレードオフは構造化因子とデータ説明因子の間にある、「全ての特徴量やイベントが相互に強い関連を持つことはないので、特徴量やイベントの数が増えるほど構造が失われていく」という一般的傾向による。そして特徴量数増加因子とイベント数増加因子間にもトレードオフがある。なお、Matchability基準の背景には「実世界情報における特定の因果関係は、特定の特徴量間の関係に反映する」という先入観があるとも言える。
Matchability基準は情報源の内部構造を推定するための評価基準ではあるが、与えられた問題空間全体を対象とせず、部分状況をを評価する点で多くの基準と違いがある。また、AIC、MDLなどの単一モデル決定のモデル選択基準と比較すると以下の点で異なる。Matchability基準はユニークな解を求めるのではなく、多数の局所解を抽出するのに用いる。第二に、Matchability基準は知識反映因子の一種である無構造化因子とは逆に構造化因子を含む。さらにMatchability基準はデータ圧縮技術と異なり、特徴選択などにおいて関連の強い特徴量を選択する。
N個の特徴量からなるイベントをD個保持する全体状況を考える。この中から任意の特徴量とイベントを選択するベクトルをd, nとする。
d = (d1, d2,…,dD): 特徴量選択ベクトルn = (n1, n2,…,nN): イベント選択ベクトル
ベクトル要素di,niは選択/非選択の二値情報であり、選択された特徴量の数をd、選択されたイベントの数をnとする。また、全ての特徴量が選択するベクトルをDとし、全てのイベントを選択するベクトルを Nとする。
状況分解は与えられた全体状況J=(D, N)に含まれる2D+N個の部分状況J=(d, n)の中から、特定の性質を持つ複数の部分状況を抽出する処理である。
今回の定式化では、各特徴量はsi個のセグメントに分割されるものとし、そのセグメント数のベクトルをs= (s1, s2,…,sD)とする。
特徴量選択ベクトルdにより指定される部分特徴量空間内には選択された特徴量毎のセグメント数の積である![]() 個のセグメントが存在する。この部分特徴量空間において任意のセグメントの選択を表わすベクトルをrdとする。
個のセグメントが存在する。この部分特徴量空間において任意のセグメントの選択を表わすベクトルをrdとする。
rd=(rd1,rd2,…,rdSd): セグメント選択ベクトル
ベクトル要素rdiは選択/非選択の二値情報であり、選択されたセグメントの数をrd(0 < rd ≦ Sd)とする。選択されたセグメント内に含まれるイベントは全て選ばれている事とし、これにより指定される部分状況をJ=(d, rd)とする。
3章でのべた、イベント数増加因子としては選択イベント数nを増加させ、構造化因子としてはセグメント数rdを減少させ、特徴量数増加因子としては全セグメント数Sdを増加させる。これら3変数を組合わせてMatchability基準を以下のように定義する。
C1, C2, C3 は正の定数n/N :部分状況に含まれるイベント数の比率
n/rd:セグメント毎の選択イベント数の平均値
rd/Sd:部分特徴量空間における選択セグメント数の空間占有率
本来、Matchable状況の探索は、全体状況J=(D, N)から選択する特徴量とイベントが変化する空間においてMatchability基準の極大値となる部分状況J=(d, n)探索する処理である。しかし、探索を高速化するために、セグメントを利用してMatchable状況J=(d, rd)を抽出する。
以下に探索の手順を説明する。
2)dによって決定される部分特徴量空間においてセグメント選択方向に関する評価が極大となるセグメント選択ベクトルrdを探索する。
3)2)で選ばれたセグメント選択ベクトルrdが、特徴量選択の変化に対して極大であればMatchable状況である。
状況分解の効果を示すシミュレーションを行った。例題では、Fig.3に示すように3次元特徴量空間において恣意的に二つの部分状況を組み合わせた全体状況を生成した。各部分状況では、平面上に11×11個のイベントが0.1刻みの等間隔に配置される。状況Aは(x + z = 1)平面であり、状況Bは(y +z = 1)平面に対応する。
特徴量をセグメントに分割する方法は、各特徴量とも同様で[-0.05, 1.05]の区間を0.1刻みで11分割した。Matchability基準の定数はC1 = 1.0, C2 = 0.3, C3= 0.7とした。
状況分解を行った結果をTable 1とFig.2の右半分に示す。Matchable状況1と2はそれぞれ状況AとBに対応している。しかし、Matchable状況3はこの二つの部分状況の組み合わせで作られた新たなMatchable状況であり、x = y, x + z = 1の直線状に分布する。
|
Situation |
|
|
|
|
|
|
Whole |
|
1331 |
242 |
232 |
|
|
MS1 |
|
121 |
132 |
11 |
1.82 |
|
MS2 |
|
121 |
132 |
11 |
1.82 |
|
MS3 |
|
1331 |
22 |
11 |
1.17 |
MS: Matchable situation,
d: Number of selected features (t: selected, f: unselected)
状況分解による予測能力の向上を説明するために多価関数φ:(x,y)→z を考える。状況分解で得られた部分状況にMeBRを用いれば状況毎に分けてφMS1(0,1)=1.0, φMS2(0,1)=0.0を出力するが、単純なMeBRでは最悪の場合には二つの状況の平均値であるφ(0,1)=0.5と出力するかもしれない。また、追加実験によれば状況A(x + z = 1)の半分が欠けていてy>0.5の領域にデータが無い場合でもMS1と同様な部分状況が抽出される。この場合、MeBRでは不可能なφMS1(0,1)=1.0を得る事ができる。このように状況分離能力や汎化能力において状況分解の効果がある。
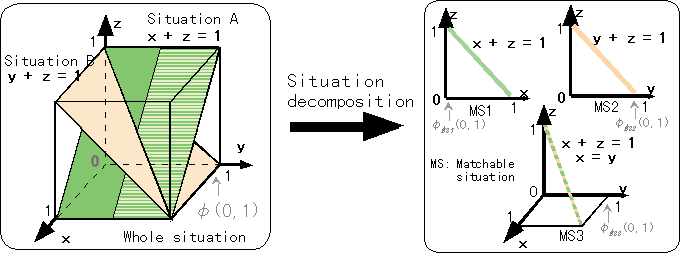
Fig.3 Events on two plains in the cube decomposed to three matchable situations
Matchabilityという新しい評価基準を用いてイベント(特徴量ベクトル)の集合である全体状況から、複数の規則性の高いMatchable状況を抽出する手法を提案した。Matchable状況を用いると、汎化により予測能力を高めることが期待できるので、データ解析、パターン認識、推論、行動決定などの前処理として利用できるだろう。
現在のMatchability基準は任意定数が含まれるので、今後はより洗練された定式化を探る必要がある。さらに高度の予測を行うためには、分割された経験を組合わせる仕組みが必要である。この種の技術は人工知能分野において盛んに研究されているが、我々もこれを目的としたパターンベースによる分散知能アーキテクチャ[7]の開発を進めている。今後はこれらの技術を組合わせて情報のScrap and Buildによる実世界知性の実現にアプローチしたいと考えている。
[2]http://www.trl.ibm.co.jp/projects/s7800/DBmining/index.htm
[3]Akutsu, T. and Takasu, A: "Inferring Approximate Functional Dependencies from Example Data", Proc. 1993 AAAI Workshop on Knowledge Discovery in Database, pp. 138-152, 1993.
[4]Akaike, H., "A new look at the statistical model identification, "IEEE, Trans. Automat. Contr., Vol.AC-19, pp.716-723, 1974.
[5]Rissanen, J., "Universal coding, information, prediction and estimation," IEEE Trans. on IT, Vol.IT-30, pp.629-636, 1984.
[6]Yamanishi, K. and Han, T. S., "Introduction to MDL from Viewpoints of Information Theory," J. JSAI, Vol.7, No.3, pp.427-434, 1992. (In Japanese)
[7]Suehiro, T., Takahashi, H. and Yamakawa, H. "Research on Real World Adaptable Autonomous Systems - Development of a Hand-to-Hand Robot," Proc. 1997 Real World Computing Symposium, pp.398-405, 1997.