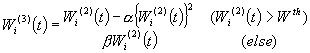For effective recognition, a recognition structure that controls the information flow among the specialized processing modules should reflect the implicit correlation structure of the environmental input. Autonomous construction of a recognition structure will lead to extensive improve in the flexibility of the adaptive recognition system. For this purpose we propose a matchability-oriented feature selection that can collect highly correlated features at each local module. Conventional techniques, which collect features that are more independent, are not suitable. Matchability is a concept derived from the recognition functions of an adaptive intelligent agent (useful for action generation) and corresponds to the probability of input data items matching stored data items in the recognition system. Proposed algorithm changes the weights attached to each feature depending on the degree of matchability of each feature. This algorithm could select highly correlated features in simple simulation.
The recognition system is an important component of an intelligent agent that transform environmental information into internal representations able for determining actions (see figure 1). The intelligent agent also contains an action generator and a critic for the overall system. To process large amounts of input data at reasonable speed, the pattern recognition (PR) system should acquire an internal recognition structure to control the information flow among the processing modules, which are specialized for particular functions. Moreover this structure should reflect the implicit correlation structure of the environmental input.
The recognition system, which can learn recognition structure by interacting with the environment without supervising, can adapt flexibly to unpredictable changes in an environment, thus helping to reduce design costs. Recognition structure learning is reduced to feature selection at each processing module level.
Techniques for estimating and selecting the features are being developed in the field of pattern recognition [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], neural networks [11, 12] and case-based reasoning [13, 14]. In supervised learning, direct and easily understandable selection measures can be used. Ether a recognition rate or an error rate is used as the selection measures depending on the system tasks. Researchers studying case-based reasoning have introduced the concept of variable weighting to indicate the utility of each feature.
We turn our attention to unsupervised learning, because we are interested in the autonomous learning system that can self-organaizingly select the necessary feature without assuming the particular task. Researchers in the pattern recognition field have proposed techniques for selecting the most effective feature subset possible in a smaller number of dimension using a quantity of information. In other words, these unsupervised compactivity-oriented approaches pursue compactness of output. Supervised learning and unsupervised learning are often combined in the pattern recognition field, and especially in the neural network field, as a network pruning technique. The compactivity oriented approach is also often used in unsupervised feature extraction techniques.
These conventional compactivity oriented feature selection techniques are not suitable for selecting features at each processing module, because the nature of the compactivity oriented approach is different from that of recognition structure learning.
We think that environmental input data have the following characteristics, which should be reflected in effective recognition structure.
1) Spatial localization of correlations
A high correlations appears in a subset of features, but they will disappear if a different kind of feature is mixed.
2) Temporal localization of correlations
A high correlations appear in a particular situation, but they will disappear if different situations are mixed.
On recognition structure learning, each processing module should be specialized to handle highly correlated partial features in a particular situation. However, the compactivity oriented feature selection technique collects more independent features with lower correlations by ignoring redundant features. Moreover the compactivity oriented approach will force consideration of different situations. From this point of view, the compactivity oriented approach is not suitable for recognition structure learning.
In the following sections, we propose a matchability-oriented feature selection, to compensate for the lacking ability of conventional compactivity oriented technique.
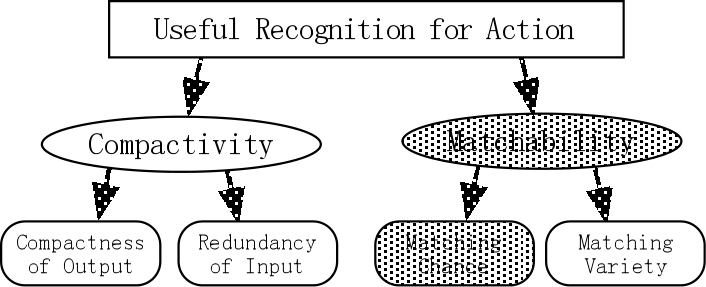
This section describes matchability and why it should be maximized. There is no final consensus on the definition of recognition, but we define it as "re-identifying something that has previously been identified," a definition that is generally popular in the computer science field. In other words, recognition is not a process that extracts an easily understandable representation for observer outside the system. Rather it is a process in which the system identifies the input data as being the same as or similar to existing data, or a composite of existing data. The PR system is part of an intelligent agent, that also has an action generator, as shown in Fig. 1. The purpose of recognition is to extract information useful to decision making and action control of an action generator. In the process of generating appropriate actions, the system retrieves previously recognized inputs that match the current input and selects an appropriate action, or an action based on an evaluation on the result of a past action. Taking our definition of recognition and the process of generation actions into consideration, it would seem that "recognition that results in an efficient action relies on obtaining compact representations that have high probabilities of identifying matching" (see Fig. 2). The measures for recognition structure learning should be based on the following:
1) Compactivity
Many studies based on the compactivity maximization approach pursue compactness of the output space that is extracted from a prescribed input feature space. Hence, their interest concentrates on emphasizing salient features or on data compression. But redundancy of input feature space is also important, because redundant space could easily be compressed. After all, compactivity relies on both compactness of the output and redundancy in the input.
2) Matchability
The main purpose of the matchability maximization approach is to increase the probability of matching future input with the system's limited store of past events. In other words, matchability is the measure for the matching ability of a system. Maximizing matchability has two practical aspects. Increased matching chance is a local and temporal characteristic that leads to selecting highly correlated partial features. The global and spatial nature of matchability leads to maximization of matching variety, which is based on the parallel operation of processing modules with a variety of responses.
The two measures described above are important for recognition structure learning. At present, however, studies of compactivity oriented feature selection/extraction are popular. In the next section we propose a trial algorithm based on the matchability-oriented approach.
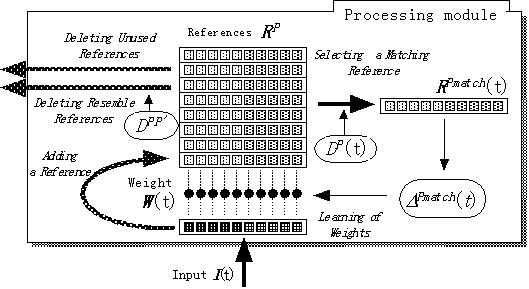
Our proposed feature selection algorithm increases the matching chance of each processing module. In order to use a sequential algorithm we introduce a weight W(t), which we attach to each feature. As shown in Fig. 3, the processing module contains reference data RP. When input data item I(t) is input to the processing module, the reference data most similar to input data item I(t) is picked up.
t : Time
W(t) = {Wi(t)} : Weight for each feature
RP = {RPi} : Reference data(P =1,2,...,n: n<=nmax)
I(t) = {Ii(t)} : Input data
The system also changes the weight, adds input data to the reference data, and deletes redundant reference data.
The following two values is caluculated for the input data.
DP(t) = Si{Wi(t) DPi(t)} Weighted distance (1)
dP(t) = Si{ DPi(t)} Unweighted distance (2)
where DPi(t) = | Ii(t) - RPi |
The reference data that has the smallest weighted distanceDP(t)is selected as the matched reference data.
Pmatch(t) = P(min DP(t) ) (3)
The weight learning rule increases the weight W(t) as the value of the local distanceDPmatchi(t) decreased. This is given by:
(4)
(k: Learning constant)
(5)
We add the following learning rule in order to average the weights W(t) over a certain range Wth and allow smaller weights can increase again. This gives the modified final weight W(t+1).
(a,b, Wth: constants, 0 < a < 1, b > 1, 0 < Wth < 1) (6)
(7)
If a new input data item I(t) is radically different from any item in the stored reference data RP, and there is room for storing, the input data is added as new reference data. That means that the weighted distance between the matched data and the input data should exceed the threshold q, for data addition. This operation is expressed by the following:
if (DPmatch(t) > q and n != nmax )
Adding I(t) to RP (8)
The system deletes a reference data item in the following cases.
1) Rarely used items: A reference data item is deleted if it is not used within 10 time periods since it was added, or if it is used only once during 30 time periods since it was added.
2) Similar items: If any of two stored reference data items are similar after the weight is changed, one of the two items is deleted. Here, threshold q is used again.
DPP' = S{Wi(t) DPP'i} (9)
Where DPP'i = | RPi - RP'i |
if(DPP' < q ) Deleting RP' (10)
We monitored changes of weight elements Wi(t) in our simulations by assigning 10 different input series to 8 parallel processing modules. The following sections describe the series of input data and processing modules and report the simulation results.
The input was a series of 10-dimensional feature vectors from time 1 to time 500. In the two class phase, feature vector at a time t was constructed by two partial vectors, each of which belonged to an independent scalar variable (see Fig. 4). The two independent variables were defined by the following equation, using rand(min, max) as a uniformly distributed random value between [min, max].
jmaxA = rand (0.0, 4.0), jmaxB = rand (0.0, 6.0) (11)
Class A was a 4-dimensional partial vector controlled by jmaxA, and Class B was a 6-dimensional partial vector controlled by jmaxB. Both of them contained noise below 0.1.
Ij(t)=|jmaxA-j+1|+rand(0.0, 1.0) (j=1,2,3,4)
Ij(t)=|jmaxB-j+5|+rand(0.0, 1.0) (j=5,6,7,8,9,10) (12)
In the random phase, each feature is an independent, uniformly distributed random, is expressed as follows
Ii(t)= rand(0.0, 1.0) (13)
Initially, each processing module has no reference data. Weights are then determined by a random value in each processing module and they are normalized.
Wi(0)=10-[1+rand(0.0,2.0)](14)
Wi(0)= Wi (0)/ Sj Wj (0) (15)
Each constant parameters are set as follows:
|
nmax |
q |
k |
Wth |
a |
b |
|
20 |
0.1 |
1.0 |
0.05 |
0.2 |
1.04 |
This proposed feature selection algorithm could select highly correlated partial features, but we do not care about temporal localization of correlation (see section 2) in it. Therefore, the proposed algorithm will behave successfully to the former two-class phase input series. However, in later simulation, input series implied temporal localization of correlation, so the weight change is unpredictable.
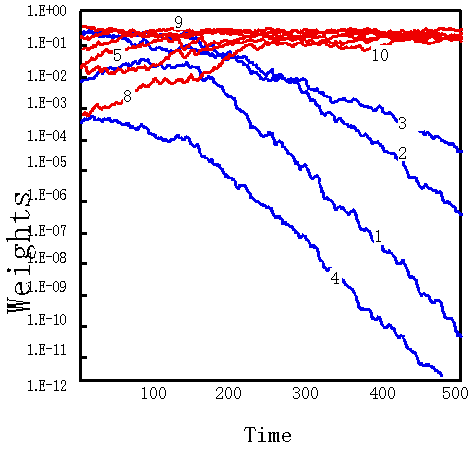
The processing modules whose weights were initialized independently were trained. Either of the two partial features were selected after a 100 to 200-time period, as shown in the sample in Fig. 5 and Table 1. In many cases the processing modules selected Class B. Partial features with high redundancy had a higher possibility of being trained.
Number of Input Series Total 0
1
2
3
4
5
6
7
8
9
Class A
0 5
0
1
3
1
1
1
1
1
14
(17.5%)
Class B
8
3
8
7
5
7
7
7
7
7
66
(82.5%)
The number of processing modules specialized to each class with different initial values, and their totals.
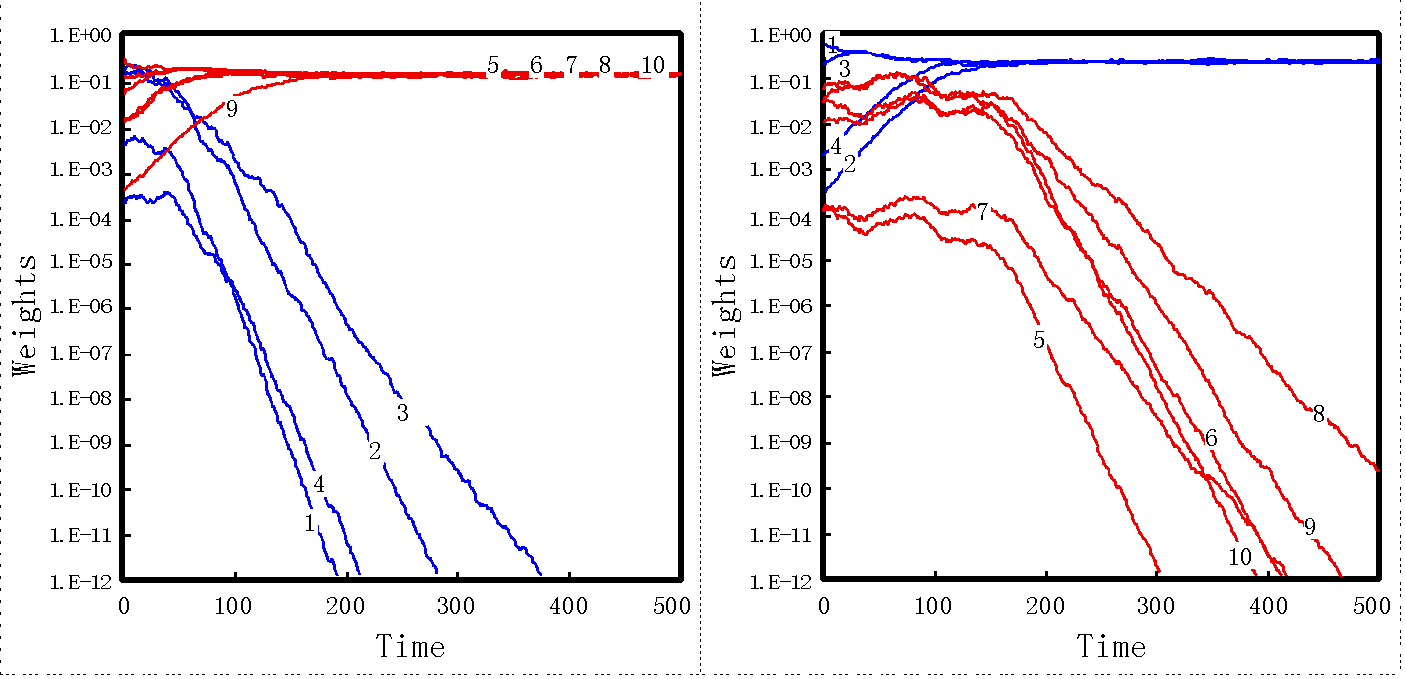
Lef figreu: Spcialized to Class B, Right figreu: Specialized to Class A.
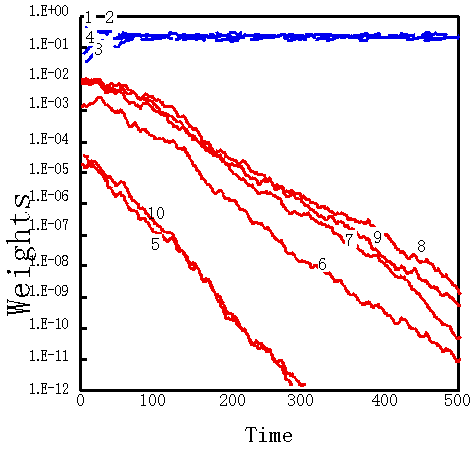
We assigned an input series to the second simulation as follows: The random phase lasted initially for 8 time periods, and the two-class phase continued for the subsequent 8 time periods. These two phases alternated repeatedly for 500 time periods. In the range of experiment of this time, our algorithm wasn't concerned with temporal localization of correlation by having included random phase either, and successfully selected partial features in many cases. These results are shown in Fig. 6 (a) and (b), and Table 2.
|
|
|
| |||||||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 | ||||
|
Class A |
|
4 |
1 |
0 |
1 |
2 |
1 |
1 |
0 |
2 |
14 |
(17.5%) | |
|
Class B |
5 |
3 |
7 |
8 |
3 |
5 |
6 |
6 |
7 |
6 |
56 |
(82.5%) | |
|
Obscure |
1 |
1 |
0 |
0 |
4 |
1 |
1 |
1 |
1 |
0 |
10 |
(12.5%) | |
Number of processing modules specialized to each class with different initial values, and their totals. In this tabulation a weight that can be classified into either class, even with insufficient training , is classified into one of the two classes. Other weights are classified as obscure.
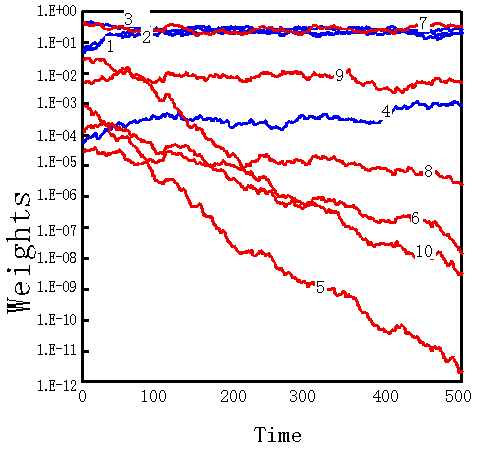
Left figre: Specialized to Class B, Center figreu: Specialized to Classs A, Right figre: Unspecialized
However, some of the processing modules did not become specialized after 500 time periods. In some cases a weight value that was a member of the almost-selected class dropped below the normalization threshold Wth and did not rise above it again, even when learning was continued longer than 500 time periods. Also, Fig. 6 (c) shows the weight change in the unspecialized processing module, even after 500 time periods. It is clear that a highly redundant partial vector tends to be chosen easily, the same as in the previous experiment.
Although the main topic of this paper is maximization of matchability, the proposed algorithm actually also relies on the compactivity approach. This means that weight averaging by eqs. (6) and (7) increases the number of selected features and the redundancy of the input, thus maximizing compactivity (see section 2). Selective reduction of the weights by eq. (4) increases the matching chances.
Balancing these two approaches allows the description with the smallest amount of reference data; if the description is not increased, the number of selected features is increased. The volume of space covered with reference data, relative to the total volume of selected feature space. Thus, selected partial feature could be effectively compressed.
Intuitively speaking, if we can determine the evaluation value that integrates compactivity and matchability, training of each processing module is understood as the local minimum search problem in the space that contains the feature to be selected and the stored reference data. Classes with more features tended to train in the simulation because the higher redundancy provided a larger leading area.
From the viewpoint of matching variety, specialization by training should be varied (see section 2). Training is a locally stable status and the frequency of occurrence is not subject to regulation. This issue cannot be solved by the local learning rule in a processing module in which only matching probability is considered. To solve this problem, some global mechanism must be implemented that interacts between modules.
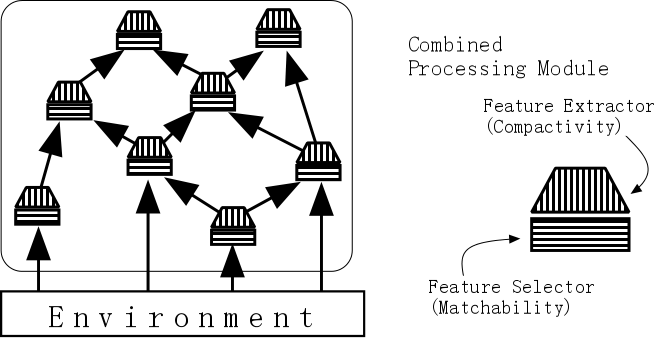
As described previously, the matchability-oriented feature selection method complements the compactivity-oriented feature extraction/selection method. Hence, in building a PR system it is essential to integrate these two methods (see Fig.7). In the combined processing module, a matchability-oriented feature selector selects an input feature for a compactivity-oriented feature extractor. The combined processing module generates a compressed representation from highly correlated partial features. Both incrementally adding the processing modules and pruning the size of the network are probable methods for autonomously constructing a recognition structure.
Despite temporal localization of the correlation, it was possible to carry out feature selection, in the latter simulation. However, weight learning will be unstable when complicated temporal localization of correlation exists. To solve this problem we must study the evaluation and selection of reference data.
Autonomous construction of an internal structure for recognition will be an effective way to make an agent's intelligence more flexible and reduce the load on the design. However, task-independent measures used by most conventional feature extraction/selection techniques aim to make the output compact. This is not suitable for recognition structure learning, which collects highly correlated features.
In this paper we have proposed matchability as a measure corresponding to the chance of input data items matching stored data items in the recognition system. This measure is suitable for recognition structure learning because its maximization causes collection of highly correlated features and is complementary to the ordinary measure compactivity. We then proposed an algorithm that selects features by modifying the weights attached to each feature so as to increase matchability. And we confirm that proposed algorithm could collect highly correlated features by computer simulations.
We also discussed the following points: (1) Conventional feature extraction mechanism should be integrated with the proposed algorithm to construct a PR system. (2) Diversity of specialization of processing modules should be globally maintained. (3) Evaluation of reference data is necessary to cope with temporal localization of the correlation.
Further, if matchability is maximized, redundant features are collected locally. Hence, this technique may be used as an information integration technique, because it can cover partially hidden input data. By including an action signal to the input features, this technique can also be used to extract sensing-action relationships that have high correlation. The matchability-oriented approach may have impact in neural networks or the brain research field, because it has potential for producing a new model design.
[1] Marill, T. and Green, D. M., (1963). "On the effectiveness of receptors in recognition system." IEEE Trans. Inform. Theory, vol. 9, pp. 11-17.
[2] Tou, J. T. and Heydoren, R. P., (1963). "Some approaches to feature extraction." Computer and Information Sciences-II, Academic Press, New York, pp. 57-89.
[3] Chien, Y. T. and Fu, K. S., (1968). "Selection and ordering of feature observations in pattern recognition systems." Inform. Contr., vol. 12, pp. 394-414.
[4] Backer, E. and Scipper, J. A. De., (1977). "On the max-min approach for feature ordering and selection." The Seminar on Pattern Recognition , Liege University, Sart-Tilman, Belgium, 2.4.1.
[5] Narendra, P. M. and Fukunaga, K., (1977). "A branch and bound algorithm for feature subset selection." IEEE Trans. Comput., vol. 26, no. 9, pp. 917-922.
[6] Pudil, P., Novovicova, J. and Kittler, J., (1994). "Floating search methods in feature selection." Pattern Recognition Letter, vol. 15, no. 11, pp. 1119-125.
[7] Gelsma, E. S., and Eden, G. (1980). "Mapping algorithms in ISPAHAN." Pattern Recognition, vol. 12, no. 3, pp. 127-136.
[8] Siadliecki, W, Siadlecka K. and Sklansky J.(1982). "An overview of mapping techniques for exploratort pattern analysis." Pattern Recognition, vol. 21, no. 5, pp 411-429.
[9] Malina, W., (1987). "Some multiclass fisher feature selection algorithms and their comparison with Karhunen-Loeve algorithms." Pattern Recognition Letter, vol. 6, no. 5, pp. 279-285.
[10] Siddiqui, K. J., Liu, Y.-H., Hay, D. R. and Suen, C. Y., (1990). "Optimal waveform feature selection using a pseudo similarity method." J. Acoustic Emission, vol. 9, no. 1 , pp. 9-16.
[11] Read, R., (1993). "Pruning Algorithms ÐA Survey." IEEE Trans. Neural Networks, vol. 4. no. 5, pp. 740-747.
[12] Mao, J. and Jain, A. K. (1995). "Artificial neural networks for feature extraction and multivariate data projection." IEEE transactions on Neural Networks, vol.6, no. 2.
[13] Aha, D. W. and Kibler, D., (1991). "Instance-based learning algorithms." Machine Learning, vol. 6, pp. 37-66.
[14] Wettschereck, D., Aha, D. W., and Mohri, T. (1995). "A review and comparative evaluation of feature weighting methods for lazy learning algorithms." (Technical Report AIC-95-012). Navy Center for Applied Research in Artificial Intelligence.