ü@
The Active Intelligence Laboratory has been conducting the project named "Real World Adaptive Autonomous Systems." On the development of the real robot system, we adopt multi-module system approach for easy incremental scaling up of the sensor-motor integrated system. To make multi-module system more adaptive, the system should flexibly integrate distributed function and change its internal structure dynamically without semantics given by supervisor. For this purpose, our proposing agent network formalizes the element processes in each agent and communication form between agents, and mainly uses non semantic communication channel on the contrary traditional AI technique. We implemented an instance of the networks on workstations. A hand-to-hand robot system was developed on the agent network. It realized robust and flexible task execution.
ü@
The Active Intelligence Laboratory has been conducting the project named "Real World Adaptive Autonomous Systems", the goal of which is to investigate technologies for flexible information processing by developing intelligent robot systems that can autonomously understand and control its working environment through active interaction with the real world [1].
The real world adaptive autonomous systems are required to cope with the uncertain, incomplete and changeable characteristics of the real world. These characteristics are typically seen in environments with people such as offices and homes. So, we are focusing our research on robots which work in such environments and cooperate with the people there under the catch phrase of "robots which coexist with humans."
While there are a number of features required for robots which coexist with humans, we focus on the issues of information processing technologies in new areas, such as flexibility, adaptability, and robustness. Specifically, we are working on ensuring reliable and robust execution of tasks by using skills, flexible and human-friendly communication by understanding actions and so forth.
To make an intelligent robot system which performs complex tasks autonomously, it is necessary to construct it as an integrated system of many kinds of functional modules, including arms, fingers, locomotions, vision sensors, touch sensors, force sensors and so on. The more modules the system has, the more intelligent it would be. We have constructed such a flexible robot system as a multi-agent system. The agents are independent and active modules of the necessary functions.
On the development of the multi-agent robot control system, we found that the flexible connection between agents and learning abilities on the connections are important for robot systems. So we propose the concept of "agent networks" to study intensively on connections between agents.
ü@
The final goal of the agent network research is realization of intelligent system as a human. The granularity of agent in this system is similar to the agent described by Minsky in "Society of agent".
There are many studies based on symbol representation in field of distributed AI [4][5]. This approach limits the learning ability of the system, because semantics must be shared all the agent beforehand. Intelligent multi-agent systems based on pattern are also studied in the machine learning community [6][7]. In these systems, signal paths are represented by explicit connection, because patterns have no semantics. Many researcher studies the learning inside the agent, but does not learning connection between agents. They studies reactive actions, but do not deliberative process with agent cooperation. Neural networks are close to the agent network, because they propagate pattern signal, but each agent in our system undertakes more complex function. Intuitively speaking, the function of one agent might be realized by more than 100 neurons. Neural network framework is very powerful its adaptability, but it is a tool for many types of applications.
To break through this stagnation, we are aiming to realize inter agent learning which changes connection between agents, generation of new agents and cooperative deliberative action without using shared semantics. Then we propose a concept of agent network that is a new model of general agent and its network. The agent network model formalizes the agent communication method and the action in each agent in pattern based domain [8]. We implemented an instance of the networks on workstations. A hand-to-hand robot system was developed on the agent network. It realized robust and flexible task execution.
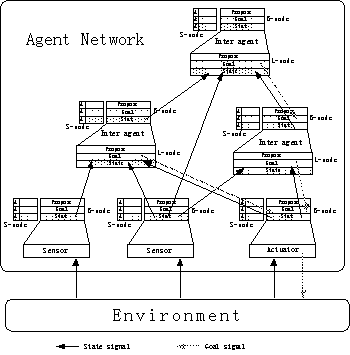
We believe that shared semantics is hard for learning, the agent network mainly uses pattern communication channel like neural networks. Without semantics each agent interprets signal differently, so the intrinsically equal signal should be bundled on same place. This constrains leads to the structure of agent network described in Figure 1. In the other word, only the relations among signals are coded by semi-fixed connection in agent network. Main parts of communication channels are node to node level that has little semantics represented by layers. Agent to agent communication channels have explicit semantics depending on node name and layers.
There are other three policies on constructing the agent network.
(1) Network structure relies on recognition system
This policy integrates the recognition and action process hierarchically.
(2) Action command is given as a goal
Command with semantics is avoided.
(3) New agent could be added step-by-step
Incremental learning becomes possible and reusing of partial system could be possible.
Communication channel between agents has six layers for every nodes.
- State layer: sends the situation of reality including sensor information, action state and internal representation. Each agent behaves as transformation function. The agent receives signal from L-node and puts the result in B-node (upward).
- Goal Layer: propagates the situation that wants to be realized. Each agent behaves as associative memory, so signals in goal layer are transformed both upward and downward.
- Propose Layer: is used for negotiation for conflict resolution.
Each layer has corresponding virtual layer for virtual mode that are VState, VGoal and VPropose layers.
One agent communicates with other agent using special nodes that have explicit semantics (Figure 2).
These nodes are pattern based communication channels (Figure 2).
- Branch node (B-node)
This node sends information generated in each agent. In recognition agent, the information from state layer of L-node is transformed and written in state layer of B-node. Internal parameter is also written on state layer of B-node.
- Leaf node (L-node)
A L-node refers one B-node of other agent and stores the connection information that is an identifier of nodes on other agent. Referring two B-node from one L-node is prohibited.
Only connection between B-node and L-node are permitted. We can add new agent with using B-node signal of existing network.
We assume that each agent can accumulate highly correlated B-node signal on other agents based on matchability criteria [9]. Then agent function is mainly depending on the selected feature and workable situation. So, agents that handle same feature should be gathered up.
From the view point of each agent, the all other agent is environment. At first the agent collects state and goal signals from connected agent and write goal on other connected agent. In other words, each agent keeps on trying to realize the given goal situation on the state layer. The final actions of the whole system emerge from chains of local goal generation, so knowledge to make action is distributed in whole the system. There are two major policies to generate goal in each agent. One is local planning that the agent searches for the goal realizing action from own knowledge. The other method relays on selecting highly evaluated action that concerns with reinforcement learning and reactive system. We introduce the critic agent and goal layer to integrate above two methods. The learning inside of the agent is based on the accumulating state signal change and evaluation of situation. The effective experience simulated with virtual mode also accumulated in each agent, and utilized in real mode operation.
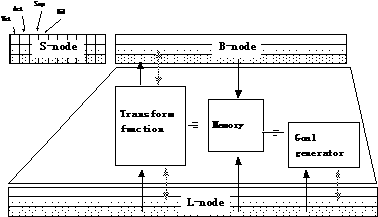
User can program many types of agent, but we assume typical agent has these three components (Figure 2).
(1) Memory
A memory accumulates experienced signals and their evaluation that agent got from L-nodeü@(B-node is contained by a case). The agent sometime reconstructs and maintains of stored data.
(2) Transformation function.
This device transforms state of L-node into state of B-node. Because this device behaves associative memory for the goal transformation, the ability of inversely transformation is desired.
(3) Goal generator
This device generates goal for realizing given goal according to present state and goal input. This device may utilize experience stored in a memory.
Agent network works asynchronously to cooperate many types of agent that has different cycle time. Anymore each agent should have reactive action to response on real time and deliberative action for planning and conflict resolution. We explain four activity cycles in real mode. Activity cycle switches depending of current values on Wat, Act and Bid nodes. Because these values decrease as time goes by, agent that is not activated falls in stop cycle after all.
(1) Stop cycle (Wat = 0, Act = 0, Bid=0)
Agent is not active at all, and is waiting for activated by select() function.
(2) Monitor cycle (Wat>0, Act = 0, Bid=0).
The agent activates when positive value was set on Wat node and when state of B-node was read. Constrained state transformation and goal association are processed. Agent does not influence other agents by generating new goal except the case collected goals are conflicting.
(3) Output cycle (Wat>0, Act>0, Bid=0).
The agent activates when positive value was set on Act node and when goal of B-node is written. The reactive goal search follows state transformation and goal association. If the agent failed reactive goal search, the agent calls for bid. If no agent can accept this request, this agent fails. This agent starts end handling at last.
(4) Bid cycle (Wat>0, Act = 0, Bid>0).
The agent activated when the other agent calls this agent for bid. The agent calls same element processes as an output cycle except not to call for bid.
The agent starts these element processes depending on activity cycle.
(1) Transformation processes
(1-1) Constrained state transformation
The agent transforms states of L-node into states of B-node by using transformation device. If a goal existed in B-node then, the agent tries to satisfy this goal while transforming state signal. This is dominant process in recognition agents.
(1-2) Goal association
The signals on goal layer both of L-node and B-node are propagated for each other, using transformation device and experience stored in the memory. The agent sometime discovers conflicts between given goal in this process.
(2) Reactive goal operation processes
(2-1) Reactive goal search
The agent generates new goal to realize goal calculated by goal association process. If appropriate new goal is not find in a short time this process fails.
(2-2) Bid request
When the reactive goal search failed, the agent sequentially calls other agent for bid to find the agent that can realize a goal on B-node. If all the requested agent failed, this agent fails too.
(2-3) End handling
If the agent filed, this agent set ON on Fil node to announce this situation. Else this agent set OFF on this node.
(3) Deliberative goal operation processes
There are some deliberative goal operation processes that are called in the virtual mode, such as "deliberative goal search", "concretization" and "abstraction".
ü@
Since the agent network has the flexible connections and the unified functions such as motion skills and vision skills, we can design and extend its behavior easily. In order to demonstrate them, we apply agent network to the hand-to-hand robot system.
The system behavior is basically decided by the sensory input. This is based on the behavior based approach and realizes robustness of the system. The system can go on working with some failure, unstable sensor input, interruption by human and so on.
The basic behavior of the hand-to-hand robot system is:
(1) if there are some objects on the table, the robot picks it up and tries to pass it to human,
(2) if there is human having an object, the robot tries to receive it and put it on the table.
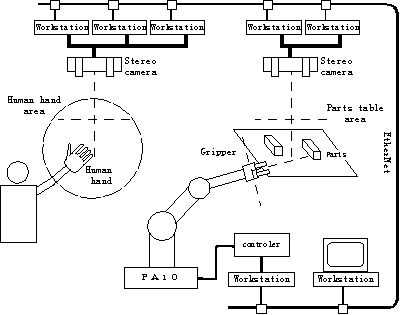
The manipulator picks and places the object in "parts table area" and it delivers and receives an object from human hand in "human hand area"(Figure 3).
Agents are working on the distributed workstations connected by the Ethernet using TCP/IP socket streams.
We prepare a stereo camera set for each work area. The stereo images are distributed to each workstation and digitized by the frame grabbers (S2200 DataCell Inc.) corresponding to its agent function. These vision agents can perform the different image processes efficiently without any competition of computer resources such as the calculation power or the data transfer on the image bus. Thus, we can use many stereo vision modules in parallel.
The manipulation system consists of a 7 D.O.F. manipulator (PA10, Mitsubishi Heavy Industries, Ltd.). and a gripper. The manipulation agent controls the manipulator by relative motion of short duration. The motion can be interrupted any time and can be adapted to changes of its environment easily. Motion of long duration is realized by successive stimuli from other agents. In each work are, the position relationships between the manipulator and the stereo camera sets are calibrated prior to the experiment.
* PA10 Agent
This agent controls the PA10 manipulator and gets information of its state directly. The motion command is given as a target position and orientation with respect to the gripper coordinate frame. The PA10 is controlled to approach to the target gradually. If the command is lost before the manipulator reaches the target, the motion decreases and stops even if it cannot reach the target. The manipulator state is the position and orientation with respect to the base coordinate frame of the manipulator. The gripper operations and states are also managed by this agent. The gripper operations are "open" or "close." The gripper states are "open without grasp", "close without grasp" or "grasp".
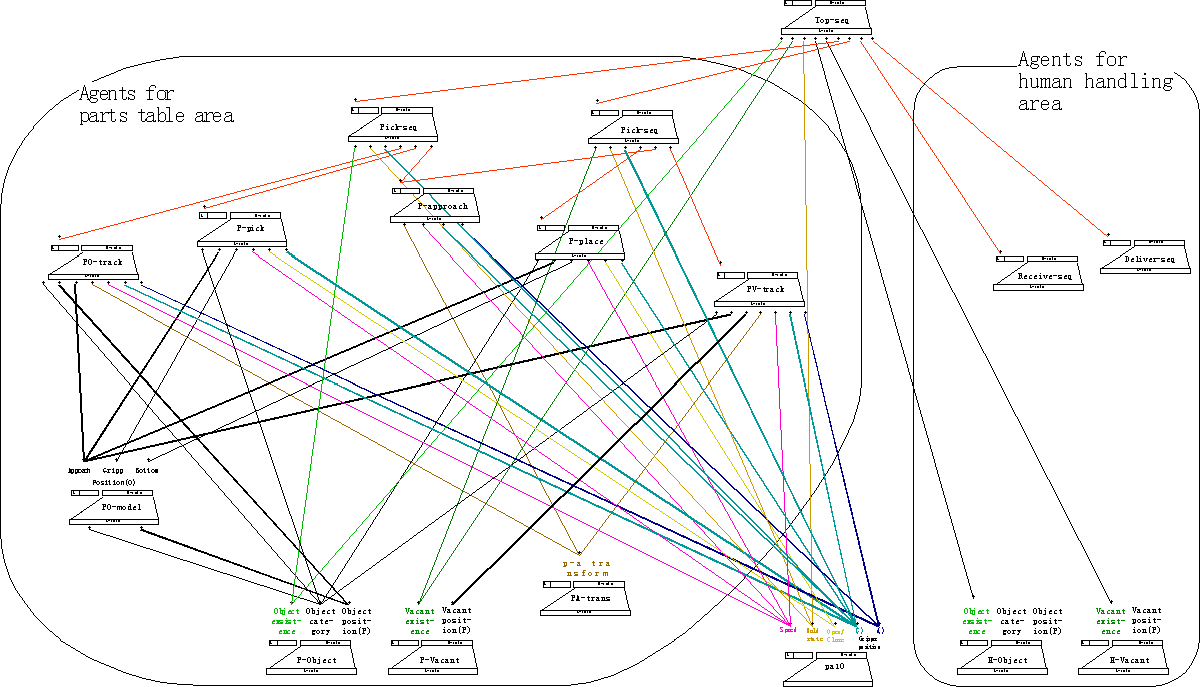
We have four classes of skill agents for the manipulation. They are approach agents, track agents, grip agents and place agents. They are classified by similarity of sensor information and behavior.
* Approach agent class
We have two approach agents, the P-approach Agent and the H-approach Agent. Those agents command the PA10 agent to move near to the target position. The target of the P-approach agent is the field of view of the parts table vision system and that of the H-approach agent is the field of view of the human hand vision system. When the gripper comes into the field of view of the vision system, a track agent can be activated for precise positioning.
* Track Agent Class
We have four track agents, the PO-track agent, the PV-track agent, the HO-track agent and the HV-track agent. Those agents track a directed target using visual information. The PO-track agent tracks an object and the PV-track agent tracks vacant space in the parts table. The HO-track agent tracks an object grasped by human hand and the HV-track agent tracks a vacant human hand. Those agents get offset distance of tracking from object information management agents.
* Pick Agent Class
We have two pick agents, the P-pick agent and the H-pick agent. "P" denotes motion in the parts table area and "H-" denotes that in the human hand area. Those agents are activated after the corresponding track agent succeeds in tracking the target object. The basic behavior of the agents is opening gripper, going to the grip position, closing the gripper and returning to the approach position. Those agents do not guarantee the success of the grasping.
* Place Agent Class
We have two place agents, the P-place agent and the H-place agent. Those agents are activated after the corresponding track agent succeeds in tracking the vacant space. The basic behavior of the agents is going to the place position, opening the gripper and returning to the approach position.
We have two object information management agents, the PO-model agent and the HO-model agent. Objects are identified by vision agents and notified as objects ID number. Basically, the ID numbers are individual for each vision system. But we set a same ID for a same object based on an assumption that a grasped object is same everywhere while it is grasped.
We have two vision coordinate management agents, the PA-trans agent and the HA-trans agent. The PA-trans agent gives the coordinate transformation between the parts table vision system and the manipulator and the HA-trans agent gives one between the human hand vision system and the manipulator.
This system has four vision agents that are supported by the several image recognition processes as shown in Figure 3. These vision agents correspond to four of the five major sensors. They report the situations and the events in real-time.
There are three stereo image programs that are processed in the independent workstations.
The human hand tracking process observes the stereo images at all times. It distinguishes the hand from others using its feature of colors that is measured in advance. If the human hand is found, its position in the 3-dimensional space is calculated and wrote on the internal blackboard.
Other process searches the objects in this area at all times. It knows the geometric models of several objects and search for them in the stereo image using the B-Rep based method [10]. It reports the existence of these objects and their positions and orientations if they exist.
The object tracking process is initiated by the agent program with its geometric data and position in the 3-dimension space. It searches for it in its neighborhood and can calculate its new position in about 30 m second.
* H-Vacant Agent
The H-Vacant agent reports the position of the 'vacant' hand that means the existence of the hand that can receive the object from the robot.
If this agent is activated, it compares the positions of the human hand and the objects. If both of them exist and distance between them is close, the 'vacant' hand exists.
* H-Object Agent
The H-Object agent reports the position of the object on the human hand. When it is activated, if the objects are on the hand, it initiates the object tracking process and reports its position and orientations until its activity is decayed.
In this area, two programs are processed as the support processes.
These are the object search program and the object tracking program that are same as of ones of the human hand area.
* P-Vacant Agent
The P-Vacant agent reports the position of the 'vacant' place that means the existence of the area where the object can be placed.
If this agent is activated, it searches for free space and reports its position using the object data.
If the table is filled by the objects, it reports the inexistence of the free space.
* P-Object Agent
The P-Object agent reports its position on the table. When it is activated, if the objects are on the table, it initiates the object tracking process and reports in real-time.
Five agents controls a task sequence of demonstration system.
* Top Sequence Agent
This agent controls sequence flow in top level. This agent switches sub-sequence depending on both object and vacant space existence in both parts-table area and human hand area and object holding state of the gripper of the manipulator. Other four control agents control sub-sequences.
* Pick Sequence Agent
This agent controls the sequence that the vacant gripper picks up an object in parts-table area. This control sequence is effective when the gripper doesn't hold an object and an object exists in parts-table area. If the gripper sits on approach position for the object, this agent activates the P-pick agent. Else if the gripper sits in field of view of part-table area vision system, this agent activates the PO-track agent. Else this agent activates the P-approach agent.
* Place Sequence Agent
This agent controls the sequence that the gripper put down the grasping object on the parts table. This control sequence is effective when the gripper holds an object and a vacant space exists in parts-table area. If the gripper sits on approach position for the vacant space, this agent activates P-place agent. Else if the gripper sits in field of view of part-table area vision system, this agent activates the PV-track agent. Else this agent activates the P-approach agent.
* Deliver Sequence Agent
This agent controls the sequence that the gripper delivers the grasping object to the human hand in human-hand area. This control sequence is effective when the gripper holds an object and vacant hand exists in the human hand area. If the gripper sits on approach position for the vacant hand, this agent activates H-place agent. Else if the gripper sits in field of view of human-hand vision system, this agent activates the HV-track agent. Else this agent activates the H-approach agent.
* Receive Sequence Agent
This agent controls the sequence that the vacant gripper receives object from the human hand in human hand area. This control sequence is effective when the gripper does not hold an object and an object exists on human hand on human-hand area. If the gripper sits on approach position for the object on the human hand, this agent activates the H-pick agent. Else if the gripper sits in field of view of the human-hand vision system, this agent activates the HO-track agent. Else this agent activates the H-approach agent.
Combination of the output of the P-Vacant and P-Object gives the state at the parts table area as shown in Table 1. The state "none" means the state cannot exist, e. i., there is no such state that there is no object and no vacant place. The state "F" means the parts table is full. The state "E" means the parts table is empty. The state "O" means there are some objects and vacant place on parts table.
Combination of the output of the H-Vacant and H-Object gives the state at the human hand table area as shown in Table 2. The state "N" means there is no hand. The state "F" means there is a hand with an object. The state "E" means there is a hand without objects. The state "none" means the state cannot exist.
ü@
|
P-Vacant |
P-Object |
State |
|
0 |
0 |
none |
|
0 |
1 |
E |
|
1 |
0 |
F |
|
1 |
1 |
O |
|
H-Vacant |
H-Object |
State |
|
0 |
0 |
N |
|
0 |
1 |
F |
|
1 |
0 |
E |
|
1 |
1 |
none |
We have the major sensor states by combining the gripper state with above two. The gripper state "U" means that the gripper grasps nothing and the "G" means it grasps something. We did not distinguish two ungrasp states, "open without grasp" and "close without grasp," in this experiment.
We design the system behavior by assigning the control agents to be activated to the states as shown in Table 3.
ü@
|
Parts Table |
Human Hand |
Gripper |
Agent |
|
E |
N |
U |
Top |
|
E |
N |
G |
Place |
|
E |
E |
U |
Top |
|
E |
E |
G |
Deliver |
|
E |
F |
U |
Receive |
|
E |
F |
G |
Place |
|
O |
N |
U |
Pick |
|
O |
N |
G |
Place |
|
O |
E |
U |
Pick |
|
O |
E |
G |
Deliver |
|
O |
F |
U |
Receive |
|
O |
F |
G |
Place |
|
F |
N |
U |
Pick |
|
F |
N |
G |
Top |
|
F |
E |
U |
Pick |
|
F |
E |
G |
Deliver |
|
F |
F |
U |
Receive |
|
F |
F |
G |
Top |
ü@
The connection of agents of the hand-to-hand robot system is shown in Figure 5.
The basic behavior described at the top of this section has ambiguity, i. e., conflicts in conditions and oscillation between conditions and results. For example, the state 1 in Table 3 satisfies the conditions of behavior (1) and (2) described there. In our experiment, we avoided those conflicts by assigning one major action to each major sensor state exclusively. The criterion is to respect human will.
This system sometime behaves natural oscillatory actions (for example, the arrow 2 in Table 3). There is nothing to do except those actions. Other oscillations (for example, the arrow 3 in Table 3) are unnatural. There is a conflict between the initial aim of those actions. But the difference between "natural" and "unnatural" just depends on view of human. If the robot passes an object to a human hand and then receives it soon, it looks unnatural. On the other hand, if the robot passes an object to a human hand and the hand stays there with the object for a while, it looks rather natural for the robot to receive it again. So we solved the problem of oscillation by adjusting the time constant of decay of agent's activity manually.
ü@
We proposed a concept of agent network that is a new system integration method, a new model of general agent and its network. We formalized the agent communication method in pattern based domain and extract element processes in each agent. So the agent network relies on the pattern based communication method, it has a potential to realized flexible learning ability. Using this model, we can attack more ambitious problems such as planning, conflict resolution, negotiation and learning in pattern based domain, on the next research step.
We implemented an instance of the networks on workstations. A hand-to-hand robot system was developed on the agent network model. The system behavior is basically decided by the sensory input. The system can go on working with some failure, unstable sensor input, interruption by human and so on. It realized robust and flexible task execution.
ü@
The authors express their gratitude to Dr. shimada and Dr. Oka at RWCP for their encouragement and support of this work, and to the members of the Robotic Group at ETL and RWCP for their valuable discussion and comments. The authors express their special thanks to Mr. Youich Ishiwata for his everyday research discussion and Mr. Kenji Konaka for his helpful programming.
ü@
[1] Suehiro, T., Watanabe, N., Sugimoto, K. and Takahashi, H., "Development of a Robot That Coexist with Human," RWC Technical Report, TR-94001, pp.97-98 (1994).
[2] Suehiro, T. and Kitagaki, K., "A Multi-agent Based Implementation of Task Coordinate Servo for the DD Manipulator:ETA3", IROS'95, pp.459-465 (1995).
[3] Suehiro, T. and Kitagaki, K., "A Multi-agent Based Implementation of Robot Skills," ICRA'96, pp.2976-2981 (1996).
[4] Ephrati, E., Rosenschein, J. S., "Divide and Conquer in Multiü]agent Planning," Proc. 12th Natl. Conf. Artif. Intell., vol.1, pp.375-380 (1994).
[5] Osawa, E., Tokoro, M., "Collaborative Plan Construction for Multiagent Planning," IPSJ-SIG-AI-77, vol.91, no.62, pp.127-138 (1991).
[6] Singh, S. P., "Reinforcement Learning with a Hierarchy of Abstract Models," Proc. 10th Natl. Conf. Artif. Intell., pp.202-207 (1992).
[7] Tham, C. K., "Reinforcement Learning of Multiple Tasks using a Hierarchical CMAC Architecture," Rob. Auton. Syst., vol.15, no.4, pp.247-274(1995).
[8] Yamakawa, H., "Pattern based Intelligent System - Speculation on Symbol Grounding Problem as viewd from Learning Ability -," Information Integration Workshop (IIW-95), pp.94-103 (1995).
[9] Yamakawa, H.," Matchability Oriented Feature Selection for Recognition Structure Learning." Proc.Int. Conf. on Pat. Reco. (ICPR-96), vol.4, pp.123-127 (1996).
[10] Takahashi, H., Suehiro, T., "Stereo Vision of the Mimic Robot", 1st Computer Vision and Visual Communication (1994).
ü@