慜摢梩偺堦晹傪懝彎偟偨姵幰偼僂傿僗僐儞僔儞僇乕僪壽戣偺傛偆側僇乕僪暘椶壽戣偵偍偄偰忬嫷偺曄壔偵懳偟偰嫮偄屌幏惈傪帵偡偙偲偑抦傜傟偰偄傞丅変乆偼丄偙偺傛偆側徢忬偑暘椶婎弨偺曄峏偲偄偆忬嫷偺曄壔偵墳偠偰丄揔愗側怓傗宍丄悢偲偄偭偨儌僟儕僥傿傊拲堄傪曄峏偡傞婡擻偑懝側傢傟偨寢壥偱偁傞偲峫偊丄忬嫷偵墳偠偰儌僟儕僥傿傊偺拲堄傪愗傝懼偊傞嫮壔妛廗儌僨儖傪採埬偟丄慜摢梩懝彎姵幰偵偍偗傞屌幏惈傪愢柧偡傞丅
拲堄丄忬嫷丄嫮壔妛廗丄寵埆惈巋寖丄僂傿僗僐儞僔儞僇乕僪壽戣丄屌幏惈丄慜摢梩丄戝擼婎掙妀丄僄乕僕僃儞僩僱僢僩儚乕僋丄儅僢僠傾價儕僥傿
丂
師悽戙忣曬張棟婎斦媄弍奐敪(RWC: Real World Computing)偱偼廬棃偺忣曬張棟媄弍偵忣曬摑崌丒妛廗宆忣曬張棟擻椡乮幚悽奅抦擻乯傪晅壛偡傞偨傔偺婎斦媄弍傪奐敪偟丄忣曬張棟偺墳梡暘栰偺奼戝傪恾傞偙偲傪栚揑偵幚悽奅忣曬抦擻媄弍 (RWI: Real World Intelligence)偺尋媶傪恑傔偰偄傞丅RWI偑宖偘傞栚昗偼幚悽奅偺忣曬傪偦偺傑傑偺宍偱庴偗庢傝丄娐嫬傗忬嫷傪擣幆傑偨偼悇應偟丄帺棩揑偵墳摎偡傞帠偑偱偒傞忣曬摑崌丒妛廗宆忣曬張棟僔僗僥儉偵昁梫側梫慺媄弍偺奐敪偱偁傝丄偦傟偵偼丄忣曬摑崌媄弍偲妛廗丒帺屓慻怐壔媄弍偑廳梫偱偁傞偲峫偊偰偄傞丅
変乆偼幚娐嫬傪帺棩揑偵堏摦偟丄僙儞僔儞僌傗懳榖摍傪捠偠偰娐嫬偲帺傜傪偲傝傑偔忣曬傪廂廤偟丄妛廗偡傞偙偲偺偱偒傞僔僗僥儉偺幚尰傪栚巜偟偰偄傞丅帺棩揑側忣曬廂廤偵傛偭偰妛廗偡傞僔僗僥儉偼丄幚悽奅偐傜偺忣曬傪庴偗丄峴摦偺寁夋傪棫埬偟丄帺敪揑偵師偺忣曬尮傪扵嶕偡傞丄偲偄偆僒僀僋儖傪孞傝曉偟幚峴偡傞丅偙偺傛偆側僔僗僥儉偵偲偭偰暋悢偺儌僟儕僥傿偺摑崌揑妛廗婡擻偲帺棩揑側忣曬廂廤偑廳梫偱偁傞丅
僸僩偼暋悢偺儌僟儕僥傿偺忣曬傪忢偵庢傝崬傒丄偦偺応偦偺応偱揔愗側忣曬傊拲堄傪岦偗傞帺棩揑側忣曬廂廤擻椡傪桳偟偰偄傞丅偮傑傝丄堎庬忣曬摑崌側偳偵尒傜傟傞拲堄偺婡擻偑僸僩偺崅搙側抦揑妶摦傪幚尰偟偰偄傞偲尵偆偙偲偑偱偒傞丅変乆偼丄僸僩偺擼偵偍偗傞抦尒偐傜丄摿偵忬嫷偵墳偠偰棙梡偡傞忣曬傪愗懼偊傞偨傔偺僗僀僢僠儞僌婡峔偑廳梫偱偁傞偲峫偊丄拲堄傪梡偄偰偙傟傪幚尰偡傞嫮壔妛廗儌僨儖偺尋媶傪峴偭偰偄傞丅
埲壓偱偼丄弶傔偵2復偱僂傿僗僐儞僔儞僇乕僪壽戣偱娤嶡偝傟傞丄慜摢梩懝彎姵幰偺忬嫷偺曄壔偵懳偡傞屌幏惈偵偮偄偰墑傋傞丅3復偱偼儅僢僠傾價儕僥傿傪棙梡偟偨忬嫷偺拪弌丄拲堄偍傛傃嫮壔妛廗偵偮偄偰弎傋丄忬嫷偵墳偠偨拲堄偺愗傝懼偊偲偦偺妛廗偺廳梫惈傪榑偠傞丅4復偱偼僄乕僕僃儞僩僱僢僩儚乕僋傪棙梡偟偨儌僨儖壔偵偮偄偰愢柧偟丄採埬偡傞妛廗儌僨儖偲僸僩偺擼偲偺斾妑傪峴偆丅嵟屻偵5復偱傑偲傔傪峴偄丄崱屻偺尋媶曽恓偵偮偄偰弎傋傞丅
丂
慜摢梩偺堦晹傪懝彎偟偨姵幰偼僂傿僗僐儞僔儞僇乕僪壽戣偺傛偆側僇乕僪暘椶壽戣偵偍偄偰忬嫷偺曄壔偵懳偟偰嫮偄屌幏惈傪帵偡偙偲偑抦傜傟偰偄傞丅[1]
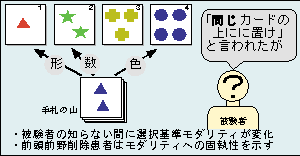
僂傿僗僐儞僔儞僇乕僪壽戣偱偼Fig.1偵帵偡傛偆側怓丄宍丄悢偺係庬椶偺慻傒崌傢偣偐傜側傞侾俀俉枃偺僇乕僪傪梡堄偟丄旐尡幰偼庤帩偪偺斀墳僇乕僪傪4枃偺暘椶僇乕僪偺壗傟偐偺壓偵抲偔傛偆巜帵偝傟傞丅旐尡幰偼幚尡幰偐傜梌偊傜傟傞暘椶偺摉斲偺忣曬偩偗偱丄怓丄宍丄悢偺壗傟偐偺暘椶婎弨偵廬偭偰惓偟偄巋寖僇乕僪傪慖戰偡傞傛偆偵妛廗傪偡傞丅偨偲偊偽丄Fig.1偺応崌丄惵偄嶰妏偑擇偮偁傞斀墳僇乕僪傪宍偱暘椶偡傟偽侾偺巋寖僇乕僪偑惓夝偲側傝丄悢偱暘椶偡傟偽俀偺巋寖僇乕僪偑惓夝偵側傞丅傑偨丄怓偱暘椶偡傟偽4偺巋寖僇乕僪偑惓夝偵側傞丅10夞懕偗偰惓夝偡傞偲丄幚尡幰偼暘椶偺婎弨傪怓偐傜宍丄偁傞偄偼悢偺傛偆偵曄偊傞丅偦偺帪丄旐尡幰偵偼暘椶偺婎弨傪曄偊偨偙偲偼帵偝側偄偺偱丄旐尡幰偼埲慜偺暘椶婎弨偱僇乕僪傪慖戰偡傞偨傔惓夝偲巚偭偰慖戰偟偨僇乕僪偑晄惓夝偱偁傞偲敾掕偝傟偰偟傑偆丅
慜摢梩懝彎姵幰偼幚尡奐巒捈屻偺弶傔偺暘椶婎弨偼妛廗偡傞偙偲偑偱偒丄幚尡幰偺寛傔偨惓偟偄婎弨偵廬偭偰僇乕僪傪暘椶偡傞偙偲偑偱偒傞傛偆偵側傞丅偟偐偟丄10夞楢懕偟偰惓夝偟偨屻丄幚尡幰偑暘椶婎弨傪曄峏偡傞偲堦斒偺旐尡幰偑怴偟偄暘椶婎弨傪怴偨偵妉摼偡傞偙偲偑偱偒傞偺偵懳偟偰丄慜摢梩懝彎姵幰偼埲慜偺暘椶婎弨偵屌幏偟丄惓偟偔僇乕僪傪暘椶偡傞偙偲偑偱偒側偄丅
僂傿僗僐儞僔儞僇乕僪壽戣偵偍偄偰弶傔偺暘椶婎弨偼妉摼偱偒傞偙偲偐傜峫偊偰丄慜摢梩懝彎姵幰偑僇乕僪傪暘椶偡傞擻椡帺懱傪幐偭偨偺偱偼側偄偙偲偼柧傜偐偱偁傞丅偱偼丄姵幰偼壗偑忈奞偝傟偨偨傔偵僞僗僋偺搑拞偱愗傝懼傢偭偨怴偟偄暘椶婎弨傪妉摼偱偒側偔側偭偨偺偱偁傠偆偐丅
変乆偼丄偙偺傛偆側徢忬偑暘椶婎弨偺曄峏偲偄偆忬嫷偺曄壔偵墳偠偰丄揔愗側怓傗宍丄悢偲偄偭偨儌僟儕僥傿傊拲堄傪曄峏偡傞婡擻偑懝側傢傟偨寢壥偱偁傞偲峫偊丄忬嫷偵墳偠偰儌僟儕僥傿傊偺拲堄傪愗傝懼偊傞嫮壔妛廗儌僨儖傪採埬偟丄慜摢梩懝彎姵幰偵偍偗傞屌幏惈傪愢柧偡傞丅
儌僟儕僥傿傊偺拲堄傪曄峏偡傞偵偼晄惓夝偵傛傞寵埆惈巋寖偑廳梫偱偁傞丅壽戣悑峴偺弶婜抜奒偵偍偄偰偳偺暘椶婎弨傕妉摼偟偰偄側偄応崌偼丄嬼慠偺慖戰偵傛偭偰惓夝偟偨嵺偵摼傜傟傞曬廣惈巋寖偺孞傝曉偟偱妛廗偑恑傒丄暘椶婎弨傪妉摼偡傞帠偑壜擻偱偁傞丅偦傟偵懳偟丄搑拞偱暘椶婎弨偑曄峏偝傟偨帪偼晄惓夝偟偨偙偲偵傛傞寵埆惈巋寖偑儌僟儕僥傿傊偺拲堄傪曄峏偡傞摦婡晅偗偲側傞丅偮傑傝丄慜摢梩懝彎姵幰偵懳偡傞僂傿僗僐儞僔儞僇乕僪壽戣偐傜偺抦尒偐傜慜摢梩偼拲堄偺妛廗偵偍偄偰丄寵埆惈巋寖偵娭學偑怺偄偲峫偊傜傟傞丅
僂傿僗僐儞僔儞僇乕僪壽戣側偳偺傛偆偵丄忬嫷偵墳偠偰堎側傞峴摦慖戰傪峴偆昁梫偑偁傞僔僗僥儉偵偍偄偰偼丄忬嫷枅偵懳墳偡傞晹暘僔僗僥儉傪梈崌偟偨傎偆偑愝寁丒妛廗側偳偺揰偐傜傒偰岠棪偑椙偄偲巚傢傟傞丅変乆偼丄婡擻儌僕儏乕儖丄戝擼旂幙椞栰丄僄乕僕僃儞僩側偳偲屇偽傟傞晹暘僔僗僥儉偺廤崌懱偲偟偰婡擻偡傞抦揑僔僗僥儉傪慜採偲偟偰尋媶傪峴偆丅
丂
忬嫷傪帠椺偲摿挜検偺慡懱廤崌偺拞偐傜丄摿掕偺晹暘帠椺偲晹暘摿挜検傪慖傃弌偟偨晹暘廤崌偱偁傞偲峫傞丅偡傞偲丄僂傿僗僐儞僔儞僇乕僪壽戣偵偍偄偰丄晹暘僔僗僥儉偑埖偆傋偒忬嫷偲偼丄娐嫬偐傜偺擖椡偲曬廣偲偵摿掕偺娭學偑懚嵼偡傞儌僟儕僥傿乕偵晅悘偟偨忬嫷偱偁傠偆丅峴摦寛掕偵桳梡側忬嫷偲偼丄梊傔拁愊偟偨忣曬偲怴偨偵擖偭偰偒偨忣曬偲偑儅僢僠儞僌偡傞婡夛傪憹戝偝偣傞傛偆側忬嫷偱偁傞丅偮傑傝丄偙偺傛偆側忬嫷傪慖戰偡傟偽抦揑僄乕僕僃儞僩偑夁嫀偺宱尡傪悇榑傗峴摦寛掕偵嵞棙梡偟傗偡偔側傞丅
変乆偼丄偙偺傛偆側惈幙傪帩偮忬嫷傪Matchable忬嫷偲屇傇偙偲偵偟丄偙偺拪弌庤朄傪Matchability巜岦偺摿挜慖戰乵2乶傪敪揥偝偣傞偙偲偱尋媶拞偟偰偄傞丅Matchable側忬嫷偵偍偄偰偼丄偦偺撪晹偵偍偄偰妛廗偡傋偒忕挿搙偑崅偔丄偟偐傕偱偒傞偩偗懡偔偺摿挜悢偲帠椺悢傪娷傓偙偲偱棙梡壙抣偑崅傑傞偩傠偆丅側偍丄忬嫷偺慖戰偼摿挜検偺慖戰傕娷傓偺偱暋悢偺儌僟儕僥傿乕娫傪寢崌偡傞僀儞僞乕儌僟乕儖側峔憿惗惉偺妛廗傾儖僑儕僘儉偱偁傞偲峫偊傞偙偲傕偱偒傞丅
埲壓偵丄尰忬偵偍偗傞Matchable忬嫷偺掕媊偵偮偄偰傑偲傔傞丅
丂
忬嫷 亖 帠椺偲摿挜検偺擟堄偺僒僽僙僢僩
暥柆忬嫷 亖 憡懳僄儞僩儘僺乕偑彫偝偄(忕挿搙偑崅偄)忬嫷
Matchable忬嫷 亖 僄儞僩儘僺乕偑彫偝偔丄摿挜悢偑戝偒偔丄帠椺悢偑戝偒偄忬嫷
亖 憡懳僄儞僩儘僺乕偑彫偝偔(忕挿搙偑崅偔)丄帠椺悢偑戝偒偄忬嫷
亖 偱偒傞偩偗帠椺悢偑戝偒偄暥柆忬嫷
亖 Matchability偺嬌戝揰偲側傞忬嫷
Matchability 亖 僄儞僩儘僺乕丄摿挜悢丄帠椺悢傪摑崌偟偨昡壙検
丂
擣抦壢妛偵偍偄偰拲堄偺婡擻偑忣曬偺慖戰偱偁傞揰偵偮偄偰偼媍榑偼傎傏堦抳偡傞偑丄偦偺昁梫惈偺婲尮偲偟偰丄乽擼偺張棟擻椡偑尷奅梕検乿偲丄乽峴摦偺偨傔偺慖戰乿偺壗傟偐偵偮偄偰偼暿傟偰偄傞丅
崱夞偺変乆偺棫応偼屻幰偱偁傝丄拲堄偺昁梫惈偼丄忬嫷偵墳偠偰棙梡偡傞忣曬傪愗懼偊傞偨傔偺僗僀僢僠儞僌婡峔偺昁梫惈偵婎偯偔丅
僗僀僢僠儞僌(忣曬慖戰)婡峔偺昁梫惈
偙偺壽戣偱偼僇乕僪偺摨堦惈偺敾抐傪忬嫷偵墳偠偰儌僟儕僥傿傪愗懼偊偮偮丄嵟廔揑偵僇乕僪傪抲偔偲偄偆堦掕偺峴摦偵寢傃晅傞丅偙偺傛偆偵堎側傞擖椡傪摨堦偺摦嶌偵寢傃晅傞偵偼撪晹婡峔偺壗傟偐偺抜奒偵忬嫷偵埶懚偡傞擣幆婡峔偐傜埶懚偟側偄摦嶌婡峔傊偺僗僀僢僠儞僌偑昁梫偲側傞丅
僗僀僢僠儞僌柍偟偱偼摦嶌晹暘傪嵞棙梡偱偒側偄偺偱丄椺偊偽怓偵傛偭偰暘偗傞偨傔偺庤偲宍偵傛偭偰暘偗傞偨傔偺庤傪撈棫偵梡堄偡傞偙偲偵側傝丄偁傑傝偵傕旕岠棪揑偱偁傞丅
嵎偟懼偊偵傛傞僗僀僢僠儞僌婡峔偲偦偺栤戣揰
偁傞晹暘僔僗僥儉偑懠偺暋悢晹暘僔僗僥儉偺堎側傞撪晹昞尰傊偺愙懕傪嵎偟懼偊傞僗僀僢僠儞僌婡峔傪峫偊傞偙偲偑偱偒傞(Fig.2 嶲徠)丅恖堊揑偵愝寁偝傟偨暘嶶張棟僔僗僥儉偱偼撪晹昞尰偵僙儅儞僥傿僋僗偑梌偊傜傟傞偺偱嵎偟懼偊傪峴偆偙偲偼梕堈偱偁傞丅
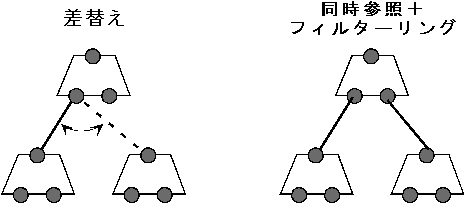
偟偐偟丄妛廗擻椡傪崅傔傞偨傔偵僙儅儞僥傿僋僗傪嬌椡攔彍偟偨僷僞乕儞儀乕僗偺僔僗僥儉乵3乶偱偼丄撪晹忣曬偑昗弨壔偝傟側偄偺偱丄堎側傞撪晹昞尰傪摨堦帇偱偒側偄丅(椺偊偽怓偑摨偠偲偄偆撪晹昞尰偲丄宍偑摨偠偲偄偆撪晹昞尰偼堎側傞)
傛偭偰丄偙偺庬偺僔僗僥儉偱偼丄嵎偟懼偊偵傛傞僗僀僢僠儞僌偼憐掕晄擻偱偁傞乮僄乕僕僃儞僩僱僢僩儚乕僋偵偍偄偰傕摨偠乯丅偪側傒偵惗懱偺擼傪峫偊偨応崌偼偍偦傜偔晹昳偺惈幙忋抁帪娫偱愙懕傪嵎偟懼偊傞傞偙偲偼擄偟偄偱偁傠偆丅
摨帪嶲徠偲僼傿儖僞乕儕儞僌偵傛傞僗僀僢僠儞僌
偦偙偱丄偁傞晹暘僔僗僥儉偑懠偺暋悢偺晹暘僔僗僥儉偵摨帪偵愙懕偡傞(摨帪嶲徠)偲嫟偵丄偦傟傜傪忬嫷偵墳偠偰僼傿儖僞乕儕儞僌偡傞曽朄偱僗僀僢僠儞僌婡峔傪幚尰偡傞丅偮傑傝丄変乆偼丄拲堄偼僗僀僢僠儞僌婡峔偺僼傿儖僞乕儕儞僌惂屼偺偨傔偵昁梫偱偁傞偲峫偊傞丅
丂
変乆偑庢傝埖偆拲堄怣崋偺惈幙偵偮偄偰弎傋傞丅偙偙偱偼奜奅偐傜偺擖椡偦傟帺懱丄偍傛傃丄偦傟偑曄壔傪庴偗偨忣曬傪忬懺忣曬偲屇傇偙偲偵偡傞丅
丂
(1)拲堄偺婡擻偼忬懺忣曬傪僼傿儖僞乕儕儞僌偡傞偙偲偱偁傞
(2)拲堄偼撪揑側峴摦偱偁傞
(3)拲堄偺棻搙偼忬懺偺奺梫慺枅傑偨偼晹暘僔僗僥儉枅偵梌偊傜傟傞(徻偟偔偼屻弎)
(4)拲堄偼忬懺偺傛偆偵曄姺偝傟偰揱攄偝傟傞偙偲偼側偄(梊應偼揱攄偡傞)
(5)拲堄摨巙偺嫞崌偼Winner take all側偳偺嬊強揑側張棟偵傛傝夝徚偝傟傞
丂
僂傿僗僐儞僔儞僇乕僪壽戣偵偍偄偰丄偙偙偱偺拲堄偼丄儌僟儕僥傿偺慖戰偲偄偆撪揑側峴摦偱偁傝丄奺擣幆僄乕僕僃儞僩偺弌椡偺桳岠惈傪惂屼偡傞偙偲偱僼傿儖僞乕儕儞僌偡傞丅
丂
杮峞偱偺嫽枴偼丄忬嫷偺曄壔偵墳偠偰拲堄偡傞儌僟儕僥傿傪愗懼偊傞婡擻傪嫮壔妛廗偵傛傝妉摼偡傞偙偲偵偁傞丄傛偭偰僞僗僋偺惉斲偵墳偠偰曬廣乛敱傪梌偊傞昡壙婡峔傕晅偗壛偊傜傟偰偄傞丅杮峞偱偼昡壙偺婡峔偼梌偊傜傟偨傕偺偲偟丄僞僗僋偺惉斲偵暪偣偰捈偪偵昡壙偑峴傢傟傞扨弮側傕偺傪壖掕偡傞丅
拲堄惗惉僄乕僕僃儞僩偑拲堄傪梌偊傞峴摦偼妛廗慜偵偼儔儞僟儉偵峴傢傟傞偑丄昡壙偵婎偯偄偰惉岟偟偨拲堄峴摦偑嫮壔偝傟傞丅偮傑傝壽戣悑峴偺弶婜抜奒偱偼丄嬼慠偵惓偟偄儌僟儕僥傿偵拲堄傪岦偗偰惓夝偟偨嵺偵摼傜傟傞嫮壔怣崋偺孞傝曉偟偱妛廗偑恑傒丄懨摉側拲堄峴摦偑妉摼偝傟傞丅傛偭偰丄慖戰婎弨偺儌僟儕僥傿偑曄壔偟側偄扨堦忬嫷偺傕偲偱偼乮偨偲偊偽丄怓偵偩偗拲栚偟偰慖傃偮偯偗傟偽椙偄傛偆側応崌乯丄師戞偵惓偟偄拲堄偍傛傃偦傟偵婎偯偔峴摦傪妛廗偡傞丅
丂
僂傿僗僐儞僔儞僇乕僪壽戣偵偍偄偰丄慜摢梩懝彎姵幰偼偼偠傔偺堦搙偩偗忬嫷偵揔墳偡傞偙偲偵惉岟偡傞偑丄忬嫷偺曄峏偵捛廬偱偒側偄嫮偄屌幏惈傪帵偡偙偲傪徻偟偔専摙偟偰傒傞丅
堦搙栚偺忬嫷偵懳偟偰惓偟偄拲堄峴摦妉摼偡傞偵偼昡壙偑憹壛偟偨捈慜偺峴摦傪嫮壔偱偒傟偽壜擻偱偁傞偑丄曄壔偟偨忬嫷偵揔墳偡傞偵偼偡偱偵妉摼偟偨拲堄峴摦傪昡壙偺尭彮帪偵曄峏偝偣傞偙偲偑昁梫偲側傞丅偮傑傝丄慜摢梩懝彎姵幰偺儌僟儕僥傿偵懳偡傞屌幏惈偼丄昡壙偺尭彮偵敽偆妛廗偵偍偗傞忈奞偲峫偊傜傟傞丅
偦偙偱丄変乆偼昡壙偑尭彮偟偨偲偒偵婲偒傞媡岦偒偺嫮壔妛廗偵拲栚偟偰尋媶傪恑傔傞偙偲偵偡傞丅昡壙偑憹戝偡傞偲偒偵偼扨弮偵捈慜偺峴摦傪嫮壔偡傟偽椙偄偺偵斾傋丄昡壙偑尭彮偡傞嵺偺嫮壔婯懃偼扨弮偵偼掕媊偱偒側偄丅
偙偙偱偼丄偡偱偵専摙偟偨昡壙尭彮帪偺偵偍偗傞嫮壔婯懃偵偮偄偰梾楍偡傞偵棷傔傞丅
丂
(1)扙嫮壔乮朰媝)
昡壙尭彮帪偵峴偆峴摦偺儔儞僟儉惈傪憹戝偝偣偰丄嫮壔偝傟偨峴摦傪朰媝偡傞丅
(2)媡嫮壔乮 媡偺僷僞乕儞傪嫮壔偡傞乯
昡壙尭彮帪偺捈慜峴摦偵懳偡傞僷僞乕儞揑側斀懳峴摦傪嫮壔偡傞丅
(3)幐攕斲掕乮 幐攕偟偨峴摦偩偗傪斲掕偡傞乯
昡壙尭彮帪偺捈慜峴摦偺慖戰妋棪傪尭彮偝偣偰丄摨偠幐攕傪旔偗傞丅
丂
僄乕僕僃儞僩僱僢僩儚乕僋偼僯儏乕儔儖僱僢僩儚乕僋偺傛偆偵愙懕偝傟偨崅婡擻偺僄乕僕僃儞僩偵傛傞僱僢僩儚乕僋儌僨儖偱丄偙傟傑偱昅幰傜偑抦揑儘儃僢僩僔僗僥儉側偳偵揔梡偟偰偒偨乵4乶丅
廮擃側妛廗擻椡偺幚尰傪栚巜偡僄乕僕僃儞僩僱僢僩儚乕僋偱偼愝寁幰偑奜晹偐傜梌偊傞僙儅儞僥傿僋僗傪嬌椡尭傜偟偰偄傞偺偱丄僄乕僕僃儞僩娫偺捠怣偼幚悢抣偺儀僋僩儖偺傒偲偟偨娐嫬偵懳偡傞擣幆僔僗僥儉偺峔惉傪偲偭偰偄傞丅傑偨丄捠忢僔僗僥儉撪偺堦晹偺僄乕僕僃儞僩偺傒偑摦嶌偡傞偺偱丄旕摦嶌帪偺忣曬偼柍岠偱偁傞丅偙傟傪昞傢偡偨傔偵捠怣偝傟傞忣曬偵偼桳岠抣(Validity)偑晅壛偝傟偰偄傞丅
奺僄乕僕僃儞僩偺捠怣扨埵偲側傞僲乕僪偵偼埲壓偺3庬椶偑偁傞丅
Special node(S-node) 妶摦搙側偳梊傔堄枴晅偗偝傟偨忣曬偺僲乕僪丅
Branch node (B-node) 偦偺僄乕僕僃儞僩偑惗惉丄娗棟偟偰偄傞忣曬偺僲乕僪丅
Leaf node (L-node) 懠偺僄乕僕僃儞僩偑惗惉丄娗棟偟偰偄傞忣曬偺擖弌椡梡偺僲乕僪丅
丂
偙傟傜偺僲乕僪偼偦傟偧傟丄儗僀儎傪傕偭偰偍傝丄
State layer: 奜奅偐傜偺擖椡偦傟帺懱丄偍傛傃丄偦傟偑曄姺傪庴偗偨忣曬
Goal layer: 幚尰偟偨偄忬懺傪昞傢偡
Attention state layer: B-node偵偍偗傞拲堄偺尰忬
Attention goal layer: B-node偵偍偄偰幚尰偟偨偄拲堄偺忬懺
丂
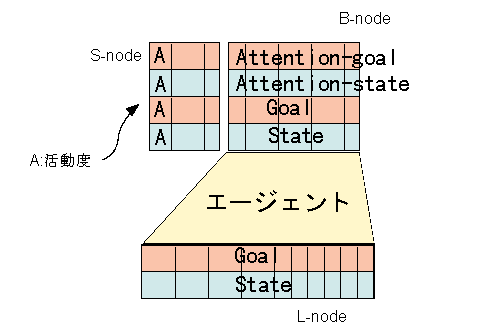
僄乕僕僃儞僩娫偺愙懕偼B-node(S-node)偲L-node偲偺娫偱側偝傟傞丅奺僄乕僕僃儞僩偼丄懠偺僄乕僕僃儞僩偐傜梌偊傜傟偨Goal傪幚尰偡傞傛偆偵摦嶌傪峴偆丅
丂
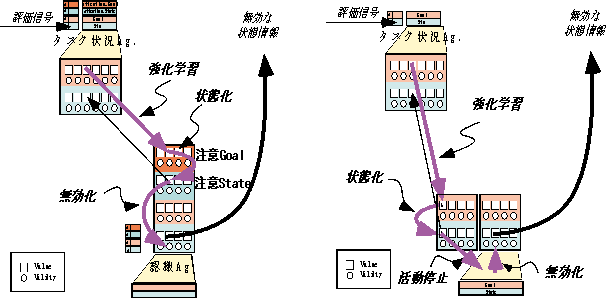
僂傿僗僐儞僔儞僇乕僪壽戣傪僔儈儏儗乕僩偡傞儌僨儖偲偟偰怓丄宍丄悢傪擣幆偡傞僄乕僕僃儞僩偲偦偺忣曬傪摑崌偡傞僄乕僕僃儞僩偍傛傃拲堄惗惉僄乕僕僃儞僩偵傛偭偰僄乕僕僃儞僩僱僢僩儚乕僋傪峔惉偟丄偝傜偵昡壙婡峔傪愝抲偡傞丅擣幆僄乕僕僃儞僩偼丄儌僟儕僥傿乕枅偵擣幆寢壥傪弌椡偡傞丄椺偊偽悢僄乕僕僃儞僩偼夋憸拞偺僆僽僕僃僋僩悢傪弌椡偡傞丅僞僗僋忬嫷僄乕僕僃儞僩偼奺擣幆僄乕僕僃儞僩偺弌椡偵懳偟偰丄僼傿儖僞乕儕儞僌傪峴偆丅拲堄偵傛傝忬嫷傪愗懼偊傞晹暘傪拞怱偵儌僨儖壔傪峴偭偰偄傞丅斾妑寢壥傪棙梡偡傞峴摦宯偺僄乕僕僃儞僩側偳偼徣棯偟偰偄傞丅
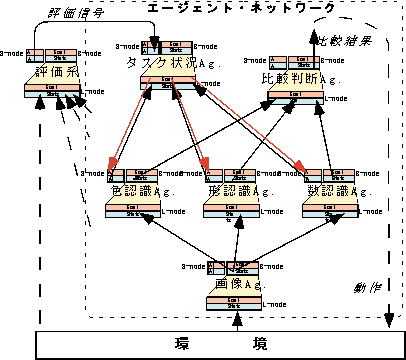
(A)僄乕僕僃儞僩僱僢僩儚乕僋
(A-1)僞僗僋忬嫷僄乕僕僃儞僩
擣幆僄乕僕僃儞僩偺弌椡偺桳岠惈傪惂屼偡傞丄昡壙偑忋徃偟偨偲偒偺拲堄偺梌偊曽傪嫮壔偡傞丅
(A-2)斾妑敾抐僄乕僕僃儞僩
奺擣幆僄乕僕僃儞僩偺寢壥傪摑崌偟偰丄擣幆拞偺僇乕僪偺曄壔傪専弌偡傞丄柍岠側擣幆忣曬偵娭偟偰偼柍帇偡傞丅
(A-3)夋憸僄乕僕僃儞僩
(A-4)怓擣幆僄乕僕僃儞僩
(A-5)宍擣幆僄乕僕僃儞僩
(A-6)悢擣幆僄乕僕僃儞僩
丂
(B)昡壙宯
娐嫬傗條乆側僄乕僕僃儞僩偺忣曬偐傜昡壙怣崋傪惗惉偡傞偑丄崱夞偺壽戣偱偼娐嫬偐傜捈愙曬廣偑梌偊傜傟傞傕偺偲偡傞丅
丂
丂
拲堄偺棻搙偲偟偰偼俀偮偺儗儀儖傪峫偊偰偄傞丅堦偮栚偵偼忬懺偺奺梫慺枅偵拲堄傪梌偊傞嵶偐偄拲堄丄擇偮栚偵偼僄乕僕僃儞僩(晹暘僔僗僥儉)枅偵偁偨偊傞拲堄偱偁傞丅嵶偐偄拲堄傪梌偊傞昁梫偑偁傞偺偐丄媡偵拲堄偺棻搙傪戝偒偔偟偰晄搒崌偑柍偄偐摍偺媍榑傪娷傔偰偺専摙偼丄崱屻偺専摙壽戣偲偟丄崱夞偼椉曽偺儌僨儖偵偮偄偰徯夘偡傞丅
壗傟偺応崌偱傕丄拲堄偵傛傝儅僗僉儞僌偝傟偨晹暘偺忬懺忣曬偺桳岠抣偑0偲側傞偙偲偱丄偦偺忬懺忣曬偑柍岠壔偝傟傞丅椺偊偽怓擣幆僄乕僕僃儞僩偑儅僗僉儞僌偝傟偨応崌偵偼斾妑敾抐僄乕僕僃儞僩偐傜尒傞偲僫僩儕僂儉儔儞僾偺壓偱尒偰偄傞傛偆偵怓偺忣曬偑柍偔側偭偰偟傑偆偺偱偁傞丅
丂
(A) 拲堄儗僀儎傪摫擖偡傞(峳偄拲堄)
嵍恾: 拲堄儗僀儎傪梡偄偨応崌丄塃恾: 妶摦搙傪梡偄偨応崌 (A:妶摦搙) 偁傞僄乕僕僃儞僩偺妶摦搙偺僑乕儖儗僀儎偑丄懠偺僄乕僕僃儞僩偺L-node僑乕儖偐傜偺彂偒崬傒偵傛傝掅壓偝偣傜傟傞偲丄偦偺妶摦搙偺忬懺儗僀儎偼捈偪偵掅壓偟偰僄乕僕僃儞僩帺懱偑掆巭僒僀僋儖偵側傞丅掆巭僒僀僋儖偱偼B-node偺忬懺忣曬偼偡傋偰柍岠壔偝傟傞丅
丂
(B) 僄乕僕僃儞僩偺妶摦搙傪惂屼偡傞乮嵶偐偄拲堄乯
偁傞僄乕僕僃儞僩偺B-node偵偍偗傞拲堄偺僑乕儖儗僀儎偑丄懠偺僄乕僕僃儞僩偺L-node僑乕儖偐傜偺彂偒崬傒偵傛傝妶惈壔偝傟傞偲丄摨偠僲乕僪偺拲堄偺忬懺儗僀儎偼捈偪偵妶惈壔偝傟傞丅堷偒懕偒摨偠僲乕僪偺忬懺儗僀儎偺忣曬偑柍岠壔偝傟傞(桳岠抣偑侽偲側傞)丅
丂
偙偙偱偼丄採埬偡傞妛廗儌僨儖偲僸僩偺擼偺婡擻偲偺斾妑傪峴偆丅採埬偡傞儌僨儖偺婎杮揑側傾僀僨傾偼拲堄偺婡峔偵娭偡傞師偺傛偆側惗棟妛偐傜偺抦尒偵傛傞丅
摿掕偺儌僟儕僥傿偵懳墳偡傞戝擼旂幙椞栰偑懚嵼偡傞
拲堄偼旂幙椞栰偺慖戰揑側妶惈壔偱偁傞
曈墢宯偱壙抣敾抐傪峴偭偰偄傞
戝擼旂幙偼摿掕偺儌僟儕僥傿偵娭偟偰椞栰枅偵婡擻暘壔偟丄奜奅偺暋嶨側娐嫬曄壔偵懳墳偡傞奜揑側僔僗僥儉偱偁傝丄堦曽丄曈墢宯偵偍偗傞壙抣敾抐僔僗僥儉偼庡偵恎懱忬嫷傊偺揔墳傪扴偭偰偄傞撪揑側僔僗僥儉偱偁傞偲峫偊傞偙偲偑偱偒傞丅
Edelman[2]偼偙傟傜擇偮偺堎側傞僔僗僥儉偑恑壔偺夁掱偱儕儞僋偡傞偙偲偵傛偭偰僸僩偺妛廗婡擻偑敪払偟偨偲弎傋偰偄傞丅偡側傢偪丄妛廗偼曈墢宯偱惗偠傞壙抣傪枮懌偡傞傛偆偵峴摦傪揔墳揑偵曄壔偝偣傞偙偲偲峫偊傜傟傞丅
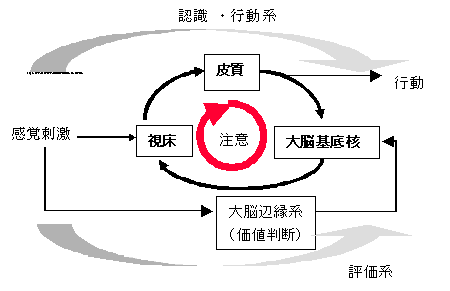
Fig.6偼僸僩偵偍偗傞戝擼旂幙丄戝擼婎掙妀偍傛傃帇彴傪寢傇怣崋偺棳傟傪恾帵偟偨傕偺偱偁傞丅戝擼旂幙亅戝擼婎掙妀亅帇彴傪寢傇夞楬偼暵夞楬偵側偭偰偍傝丄帇彴偼旂幙傪梷惂偟丄戝擼婎掙妀偼旂幙椞栰偵搳幩偡傞帇彴傪慖戰揑偵扙梷惂偡傞偺偱丄寢壥偲偟偰戝擼婎掙妀偼旂幙傪妶惈壔偡傞丅偙偺戝擼婎掙妀偵傛傞帇彴偺扙梷惂偵偼戝擼婎掙妀偵嫮偔寢崌偟偰偄傞慜摢旂幙偲曈墢宯偺栶妱偑廳梫偱偁傝丄戝擼婎掙妀偼僪乕僷儈儞恄宱嵶朎偐傜曻弌偝傟傞嫮壔怣崋傪棙梡偟偰丄嫮壔妛廗傪峴偭偰偄傞偲偺曬崘傕偁傞丅
崱夞採埬偟偨拲堄偺妛廗儌僨儖偱偼丄僄乕僕僃儞僩僱僢僩儚乕僋偼丄旂幙偲戝擼婎掙妀偺椉曽傪娷傓丅拲堄偺儗僀儎桳傝偺応崌丄戝擼婎掙妀偼Leaf goal 仺 Branch attention goal 仺 Branch attention state 仺 Branch state validity 偺楬忋偵憡摉偡傞丅拲堄儗僀儎柍偟偺応崌偱傕摨偠傛偆偵懳墳偝偣傞偙偲傕偱偒傞偑丄傓偟傠丄奺僄乕僕僃儞僩偺妶惈僲乕僪偑戝擼婎掙妀偵廔寢偟偰偄傞偲峫偊傞偙偲傕壜擻偱偁傞丅
丂
杮峞偱偼忬嫷偵墳偠偰揔愗側儌僟儕僥傿傊偺拲堄傪愗傝懼偊傞嫮壔妛廗儌僨儖傪採埬偟偨丅摉儌僨儖偼忬嫷枅偵懳墳偡傞晹暘僔僗僥儉偺廤崌懱偱偁傝丄儌僟儕僥傿偵晅悘偟偰娐嫬偐傜摼傜傟傞曬廣惈巋寖偲寵埆惈巋寖偲偺娭楢偵傛傝揔愗側峴摦傪峴偆傛偆偵妛廗偡傞偙偲偑壜擻偱偁傞丅偝傜偵丄慜摢梩懝彎姵幰偺僂傿僗僐儞僔儞僇乕僪壽戣傃偍偗傞屌幏惈偐傜偺抦尒偵傛傝丄昡壙偑尭彮偟偨偲偒偵婲偒傞媡岦偒偺嫮壔妛廗偺廳梫惈偵偮偄偰弎傋偨丅変乆偼丄堷偒懕偒Matchable忬嫷拪弌偺傾儖僑儕僘儉傪奐敪偡傞偲偲傕偵丄採埬偟偨儌僨儖傪僀儞僾儕儊儞僩偟偰僔儈儏儗乕僔儑儞偡傞梊掕偱偁傞丅
丂
崱屻傕変乆僌儖乕僾偼幚悽奅忣曬張棟敪揥傊偺峷專傪栚巜偟偰尋媶傪恑傔傞偵偁偨傝丄摉柺偼摿偵丄忬嫷偵墳偠偨拲堄傪棙梡偡傞偙偲偱忣曬摑崌傪峴偆抦揑妛廗僔僗僥儉傪僞乕僎僢僩偲偡傞梊掕偱偁傞丅
抦揑僔僗僥儉偵偍偄偰忬嫷偵墳偠偨峴摦傪峴偆擻椡偼忣曬摑崌媄弍偺堦妏傪扴偆廳梫側僥乕儅偱偁傞丅忬嫷傪棙梡偡傞偨傔偵丄傑偢偼堎側傞忬嫷傪帺摦揑偵暘椶偡傞昁梫偑偁傞偑丄偙偺僙僌儊儞僥乕僔儑儞偺婡擻傪幚尰偡傞庤抜偲偟偰丄変乆偑偙傟傑偱偵尋媶傪恑傔偰偒偨Matchability媄弍傪敪揥偝偣偰棙梡偡傞梊掕偱偁傞丅摿偵惂屼懳徾忣曬偲丄忬嫷愗懼偊巋寖偑堎側傞儌僟儕僥傿偵娷傑傟傞傛偆側応崌偵偼丄儅儖僠儌僟儖側忬嫷敾掕偑杮幙揑偵廳梫側堄枴傪帩偮偩傠偆丅
偝傜偵丄拪弌偝傟偨忬嫷傪棙梡偟偨峴摦偺惂屼偲偟偰偼昞憌揑側峴摦偺傒側傜偢丄崱夞変乆偑採埬偟偨傛偆偵拲堄傪撪晹揑側峴摦偲傒側偟偰惂屼偡傞偙偲傕抦揑擻椡偺幚尰偵峷專偡傞偲巚傢傟傞丅拲堄偺惂屼偵傛傝慖傜傟傞庡側岠壥偲偟偰偼丄忣曬偺僗僀僢僠儞僌丄晹暘婡擻偺張棟擻椡偺挷惍側偳偑偁傞偩傠偆丅
偝傜偵偙傟傜偺忣曬張棟婡峔傪娐嫬偺曄壔偵懳偟偰廮擃側傕偺偲偡傞偨傔偵偼丄條乆側妛廗婡擻傪惙傝崬傓偙偲偑晄壜寚偱偁傞丅尰嵼変乆偑庡偵専摙傪恑傔偰偄傞妛廗婡擻偼丄(1)拪弌偝傟偨忬嫷偵懳墳偡傞僄乕僕僃儞僩惗惉傪峴偆妛廗丄(2)拲堄峴摦偺昡壙偵婎偯偔嫮壔妛廗丄側偳偱偁傞丅
堦曽丄採埬偟偨儌僨儖偼僔僗僥儉峔抸傪栚巜偡懡偔偺僯儏乕儔儖僱僢僩儚乕僋尋媶偲摨條偵丄斈梡揑側抦擻僔僗僥儉偺峔抸傪栚巜偟偰偄傞偺偱丅婡擻揑偵峔惉偟偨儌僨儖偐傜惗棟妛尋媶偵壗傜偐偺帵嵈傪梌偊傞偙偲傕栚巜偟偰偄傞丅
丂